
いわゆる「AI」をPCで運用するには、GPUとVRAMをはじめとする潤沢な計算リソースが求められるところ、推論を実行するだけならばRaspberry Piでも対応できる*1。それが実用的であるかはおいて、普及機レベルのPCでも対応可能だ。
"ggerganov/ggml"*2, "gpt-2"は、RAM搭載量が8GBでも実行可能とし、 RAMを16GB搭載していれば、"gpt-j"も実行可能だ。
この投稿では、その手順と実行パフォーマンスを紹介する。テスト環境にはMicrosoft Surface Pro 4と自作のデスクトップPCを用いている。それぞれのスペックに加え、"gpt-2"、"gpt-j"は単一トークン当たりの推論パフォーマンスを示している。
| Surface Pro 4 | desktop | |
|---|---|---|
| OS | Windows 11 Pro 22H2 | Windows 11 Pro 22H2 |
| CPU | Intel Core i7-6650U | Intel Core i7-6700T |
| RAM | 8GB | 32GB |
| gpt-2 | 21~22ms | |
| gpt-j | 484~487ms |
ソースコードとモデルのダウンロード
GitHubからソースコードをダウンロードし、任意のフォルダへ展開する。この投稿では、全てのファイルを次のフォルダに格納している。このフォルダを作業フォルダと呼ぶことにする。
D:\user temp\ggml-master\
次にHugging Faceから学習済みモデルをダウンロードする。
| for gpt-2.exe | ggml-model-gpt-2-117M.bin |
| for gpt-j.exe | ggml-model-gpt-j-6B.bin |
117Mモデルが8GB RAMのPC向けだ。両方のモデルをダウンロードする必要はない。gpt-jで用いる6Bモデルは、実行に16GB RAMを要する。
実行ファイルのビルド
whisper.cの修正
"whisper.c"は、UTF-8エンコーディング上の問題を抱えており、それがビルドの妨げとなる。その回避策として、 次のトークンを"non_speech_tokes"から削除する。
"「", "」", "『", "』",

//static const std::vector<std::string> non_speech_tokens = { // "\"", "#", "(", ")", "*", "+", "/", ":", ";", "<", "=", ">", "@", "[", "\\", "]", "^", // "_", "`", "{", "|", "}", "~", "「", "」", "『", "』", "<<", ">>", "<<<", ">>>", "--", // "---", "-(", "-[", "('", "(\"", "((", "))", "(((", ")))", "[[", "]]", "{{", "}}", "♪♪", // "♪♪♪","♩", "♪", "♫", "♬", "♭", "♮", "♯" //}; static const std::vector<std::string> non_speech_tokens = { "\"", "#", "(", ")", "*", "+", "/", ":", ";", "<", "=", ">", "@", "[", "\\", "]", "^", "_", "`", "{", "|", "}", "~", "<<", ">>", "<<<", ">>>", "--", "---", "-(", "-[", "('", "(\"", "((", "))", "(((", ")))", "[[", "]]", "{{", "}}", "♪♪", "♪♪♪","♩", "♪", "♫", "♬", "♭", "♮", "♯" };
Visual Studioでのビルド
Visual Studioでビルドし、実行ファイルを生成する。この投稿では、Visual Studio 2022 Version 17.7.4を用いている。手順は次のとおりだ。
- エクスプローラーで作業フォルダへ移動し、右クリックでコンテキスト・メニューを開く。
- コンテキスト・メニューで「Visual Studioで開く」を選択する。
- Visual Studioで「cMake設定エディターを開く」を選択する。
 |
 |
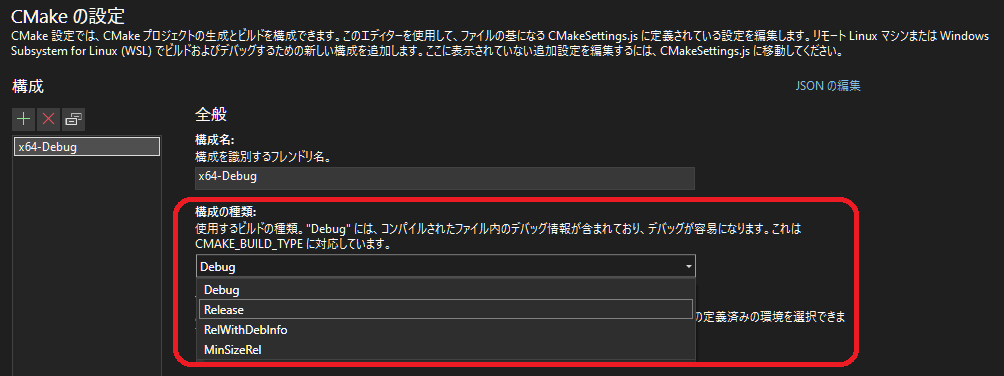
「CMakeの設定」にて
- 「構成の種類」の設定を「Release」へ変更する。
ビルド
- 「ソリューションエクスプローラー」にて"CMakeLists.txt"を右クリックし、コンテキスト・メニューを開く。
- コンテキスト・メニューで「ビルド」を選択する。新たにCMakeが生成される。
- 再び「ビルド」を選択すると、実行ファイルが生成される。
 |
 |
2度目のビルドで出力される実行ファイルは、次のフォルダへ格納される。このフォルダへ、先にダウンロードしておいたモデルもコピーする。
D:\user temp\ggml-master\out\build\x64-Debug\bin
gpt-2.exeの実行
プロンプト「Actions speak louder than」、「When in Rome, do as the」と共にgpt-2.exeを実行する。
.\gpt-2.exe -m .\ggml-model-gpt-2-117M.bin -p "Actions speak louder than" .\gpt-2.exe -m .\ggml-model-gpt-2-117M.bin -p "When in Rome, do as the"
第6世代Intel Core i7での推論パフォーマンスは、トークン当たり21~22msだ。言語モデルのサイズは239MBと、RAMに載せるのに十分な小ささだ。しかしパフォーマンスは悪くないものの、出力品質は総体的に悪い。プロンプトに続くトークンは正確に予測されているものの、生成されている文章に文脈上の一貫性がない。
 |
 |
gpt-j.exeの実行
同様のプロンプトでgpt-j.exeを実行する。
.\gpt-j.exe -m .\ggml-model-gpt-2-117M.bin -p "Actions speak louder than" .\gpt-j.exe -m .\ggml-model-gpt-2-117M.bin -p "When in Rome, do as the"
第6世代Intel Core i7での推論パフォーマンスは、トークン当たり484~487msだ。言語モデルはRAMに乗り切っているのだが、それがパフォーマンス向上に貢献することはなかった。gpt2に比べて、出力品質は優っているものの、それがパフォーマンスに見合う程度とは思えない。
 |
 |
余談
gpt-2、gpt-jともに、実行はできたものの、その出力は満足いくものではなかった。ただ、RAM=8GBの環境でも、推論を実行可能であることは確認できた。付け加えると、そのような環境でも、ある程度満足のいく出力が可能であることも、その他の投稿で示している*3。
出力品質は、環境やプログラムの違いではなく、モデルの生成に用いられた学習データに起因している。そして今やRAM=8GBのPCでも推論だけでなく、強化学習も実行可能だ*4。生成AIだからと言って、ChatGPTのように、チャット形式で、あらゆる事柄に対して汎用的に対応する必要はない。目的と用途を限定すれば、小さなモデルでも対応可能な領域は必ず存在するはずだ。
目的と用途に限定、特化した高品質なデータを用意し、それで学習モデルを生成すれば、実行環境だけでなく、目的と用途にも最適化された、より効果的なソリューションを提供できることだろう。
*1: I've sucefully runned LLaMA 7B model on my 4GB RAM Raspberry Pi 4. It's super slow about 10sec/token. But it looks we can run powerful cognitive pipelines on a cheap hardware. pic.twitter.com/XDbvM2U5GY
twitter.com