
Abstract
One of the popular topic in "AI" is GPT (Generative Pre-trained Transformer). Although it usually requires rich computational resources, running it on minimal environment as Raspberry Pi is technically possible now*1. And regardless of whether it is practical, it can run on consumer PC as well. "ggerganov/ggml"*2, "gpt-2" there made running GPT on PC with 8GB RAM. With 16GB RAM, running "gpt-j" is also possible.
This post introduces its how-to and performance. Specification of the test machine in this post is Microsoft Surface Pro 4 and the desktop PC with specs below. "gpt-2" and "gpt-j" are prediction performance per a single token.
| Surface Pro 4 | desktop | |
|---|---|---|
| OS | Windows 11 Pro 22H2 | Windows 11 Pro 22H2 |
| CPU | Intel Core i7-6650U | Intel Core i7-6700T |
| RAM | 8GB | 32GB |
| gpt-2 | 21~22ms | |
| gpt-j | 484~487ms |
Download source code and model
Download source code from GitHub, and extract it to any folder. In this post, all files are extracted under the next folder. Hereafter in this post, this folder is referred to as the working folder.
D:\user temp\ggml-master\
And download the next language model from Hugging Face.
| for gpt-2.exe | ggml-model-gpt-2-117M.bin |
| for gpt-j.exe | ggml-model-gpt-j-6B.bin |
117M model is for 8GB RAM PC. There is no need to download both models. 6B model is for gpt-j and it requires 16GB RAM.
Build execution file
Workaround for whisper.c
"whisper.c" has problems with UTF-8 encoding that prevents build process. For workaround, delete the next token from "non_speech_tokes" as following.
"「", "」", "『", "』",

//static const std::vector<std::string> non_speech_tokens = { // "\"", "#", "(", ")", "*", "+", "/", ":", ";", "<", "=", ">", "@", "[", "\\", "]", "^", // "_", "`", "{", "|", "}", "~", "「", "」", "『", "』", "<<", ">>", "<<<", ">>>", "--", // "---", "-(", "-[", "('", "(\"", "((", "))", "(((", ")))", "[[", "]]", "{{", "}}", "♪♪", // "♪♪♪","♩", "♪", "♫", "♬", "♭", "♮", "♯" //}; static const std::vector<std::string> non_speech_tokens = { "\"", "#", "(", ")", "*", "+", "/", ":", ";", "<", "=", ">", "@", "[", "\\", "]", "^", "_", "`", "{", "|", "}", "~", "<<", ">>", "<<<", ">>>", "--", "---", "-(", "-[", "('", "(\"", "((", "))", "(((", ")))", "[[", "]]", "{{", "}}", "♪♪", "♪♪♪","♩", "♪", "♫", "♬", "♭", "♮", "♯" };
Build with Visual Studio
Build an execution file with Visual Studio. Version in this post is "Visual Studio 2022 Version 17.7.4". Operate as following.
- Open the working folder in Explorer, open the context menu with right clicking
- Select "Open Visual Studio" from the menu
- Select "CMake settings editor"
 |
 |
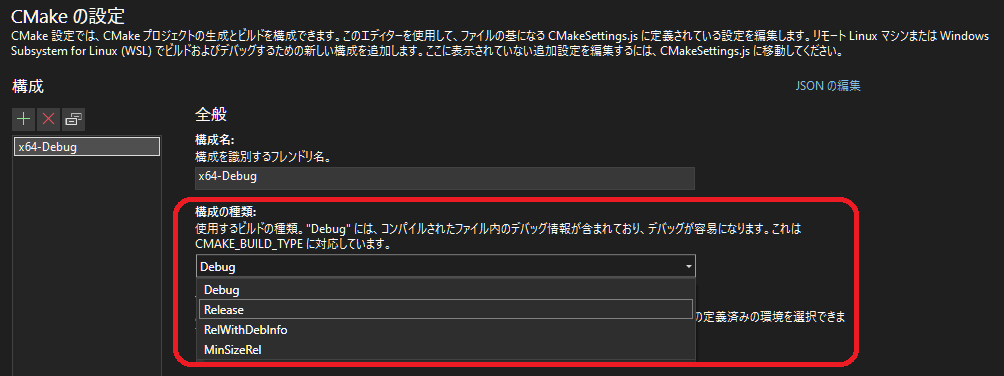
CMake configuration
- Open "CMake Settings"
- Select "Release" at "Configuration type"
Build
- Right click "CMakeLists.txt" at solution explorer, and open context menu
- Select "Build", then new CMake is generated
- Select "Build" again, then release build of binaries is generated
 |
 |
After the 2nd build, binaries are generated under the next folder. Copy the previously downloaded models to this folder, too.
D:\user temp\ggml-master\out\build\x64-Debug\bin
Run gpt-2.exe
Run gpt-2.exe with the prompt "Actions speak louder than" and "When in Rome, do as the" as
.\gpt-2.exe -m .\ggml-model-gpt-2-117M.bin -p "Actions speak louder than" .\gpt-2.exe -m .\ggml-model-gpt-2-117M.bin -p "When in Rome, do as the"
Inference performance on the 6th generation Intel Core i7 is around 21~22ms/token. Size of the language model is 239MB and enough small to put on RAM. Although performance is not bad, quality of output is relatively not good.
Token just after the prompt is correctly predicted. However, the generated sentences are less contextually consistent with the given prompts.
 |
 |
Run gpt-j.exe
Run gpt-j.exe with the same prompts as
.\gpt-j.exe -m .\ggml-model-gpt-2-117M.bin -p "Actions speak louder than" .\gpt-j.exe -m .\ggml-model-gpt-2-117M.bin -p "When in Rome, do as the"
Inference performance on the 6th generation Intel Core i7 is around 484~487ms/token. Although size of the language model is enough small to put on RAM, it doesn't contribute making performance better. The quality of the output results is better than gpt2, but not commensurate with the poor performance.
 |
 |
*1: I've sucefully runned LLaMA 7B model on my 4GB RAM Raspberry Pi 4. It's super slow about 10sec/token. But it looks we can run powerful cognitive pipelines on a cheap hardware. pic.twitter.com/XDbvM2U5GY
twitter.com