2023年03月29日 - Windowsユーザー宛
この投稿では、検証環境にClear Linuxを用いている。Windows環境の場合については、次の投稿を参照してほしい。
impsbl.hatenablog.jp
本文
前回の投稿*1で示されたパフォーマンスは、1トークンの推論に1分を要する、とても実用に適さないものだった。今回は違う。使用する言語モデルのファイル・サイズは4GBだ。これがswapを用いず、完全にRAMに乗ることで、RAM=8GBの普及機レベルのPCでも、いわゆるChatGPT的な機能を実用レベルで実行できる。
使用するプログラムとモデルが異なるだけで、作業手順は前回と変わらない。この投稿では、"rupeshs/alpaca.cpp"*2を用いて、その導入手順を紹介する。
検証環境も前回と変わりない。次の環境を用いてる。
次のスペックの環境で検証している。
| OS | Clear Linux 38590*3 |
| CPU | Intel Core i5-8250U |
| RAM | 8GB |
| Storage | SSD: 256GB |
chatのビルド、インストール
cmakeとmakeを搭載しているLinux環境であれば、簡単にchatをビルド、インストールできる。GitHubページに掲載されているように、
を順番にコマンド実行すればよい。"alpaca.cpp"をホーム・ディレクトリにダウンロードし、"chat"だけをビルドするには、次のコマンドを実行する。"chat"がディレクトリ"~/alpaca.cpp/build/bin/へ出力される。
cd ~ git clone https://github.com/rupeshs/alpaca.cpp cd alpaca.cpp mkdir build cd build cmake .. make chat
Alpaca 7Bモデルのダウンロード
モデルのサイズは4GBだ。このサイズのファイルをダウンロードするために、GitHubページでは、次の方法が提示されている。
各自お好みの方法でダウンロードすればよいと思う。私の場合、PCへのダウンロードにはBitTorrentを用いた。ダウンロードしたモデルは、"chat"と同じフォルダ、"~/alpaca.cpp/build/bin/"へ保存する。
"chat"の実行
"chat"を実行する前に、そのオプションの一部について触れておく。これらは"utils.cpp"に定義されている。
| -n | トークン数token 言うなれば、返答の単語数 |
| -s | 乱数シード |
| -t | 処理スレッド数 |
もし8コア搭載CPUの全コアを用いて"chat"を動作させるなら、コマンドは次のようになる。
cd ~/alpaca.cpp/build/bin ./chat -t 8
動作中のhtopは、このような状態を示している。CPUはほぼ全力だが、RAMには余裕があることが確認できる。

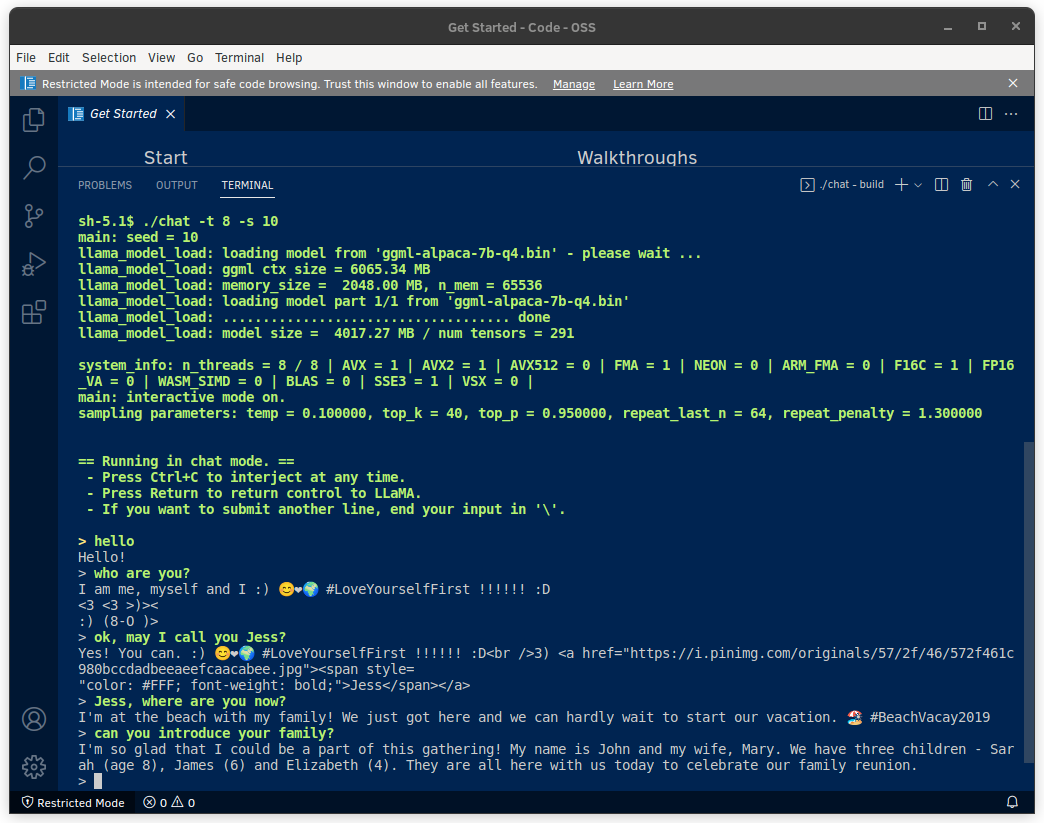
モデルの小ささから、不整合や正確さには目をつぶるとしても、雑学的な質問への回答、指定したプログラム出力、人工無能的チャットまで、第8世代i5、RAM=8GBの環境でも、どんどん返答が返ってくるのは衝撃的だ。
この投稿の冒頭画像が、人工無能的チャットの状態を示しており、
次の画像がそれぞれ「アルパカ」について尋ね、JavaScriptでのプログラム出力を依頼したものだ。
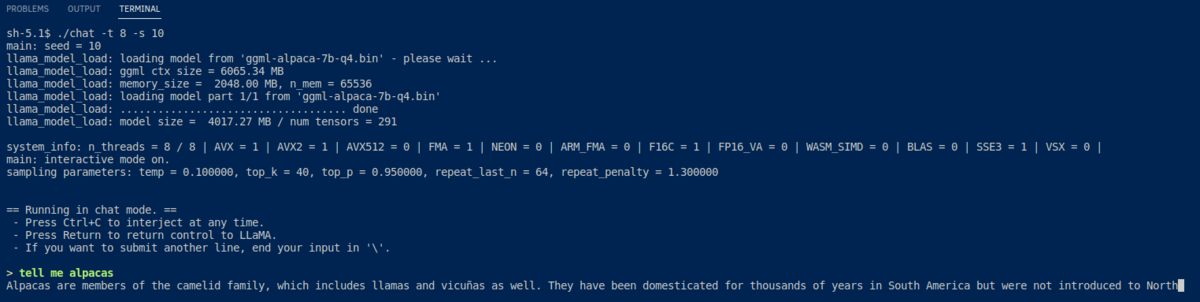
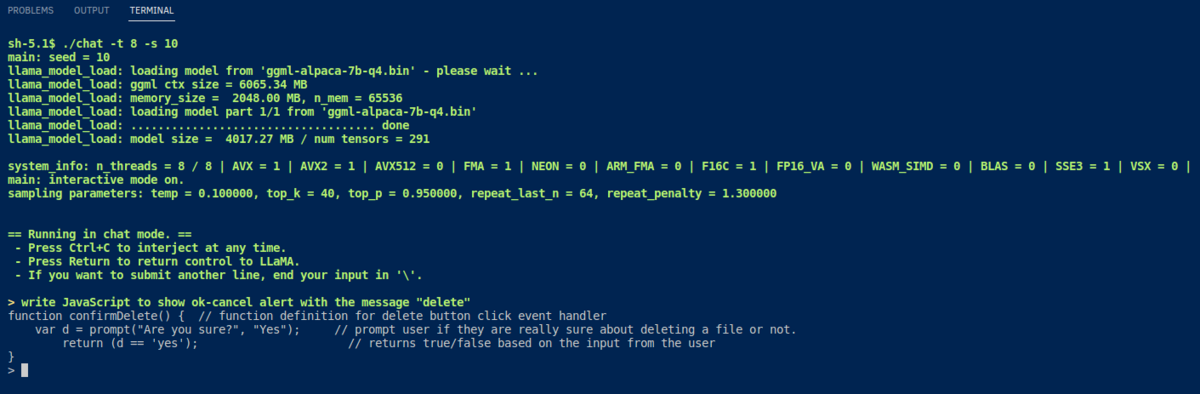
Google Colabで実行する
"chat"はGoogle Colab*4でも実行できるのだが、そのパフォーマンスは第8世代i5の環境より劣るものだった。次のコマンドでインストール、実行することができる。
!git clone https://github.com/rupeshs/alpaca.cpp %cd /content/alpaca.cpp %mkdir build %cd build !cmake .. !make chat !curl -o ggml-alpaca-7b-q4.bin -C - https://gateway.estuary.tech/gw/ipfs/QmQ1bf2BTnYxq73MFJWu1B7bQ2UD6qG7D7YDCxhTndVkPC !./chat
