2023-03-29 - To Windows user
This post is for Linux. For Windows case, please refer the next post.
impsbl.hatenablog.jp
Abstract
The last post*1 indicated unpractical performance as prediction of a single token per a minute. Performance this time is enough practical. Using smaller language model as 4GB file size. It is stored on RAM without swap, and consumer PC with 8GB RAM can run function as ChatGPT at practical level.
Just using different program and model from the last time, work procedures are common with. This post introduces the same procedure with "rupeshs/alpaca.cpp"*2.
Specification of the test machine is also common as following.
| OS | Clear Linux 38590*3 |
| CPU | Intel Core i5-8250U |
| RAM | 8GB |
| Storage | SSD: 256GB |
Build and installation of chat
In an environment that cmake and make are initially prepared as Linux, build and installation of "chat" is quite simple. As described at the GitHub page, required commands are for
- download (clone) source cord
- make a directory if required
- cmake and make
To download "alpaca.cpp" under the home directory, and build only "chat" there, commands will be
cd ~ git clone https://github.com/rupeshs/alpaca.cpp cd alpaca.cpp mkdir build cd build cmake .. make chat
Download Alpaca 7B model
The file size of this model is 4GB. The GitHub page introduces downloading it with
In any case, download it to the folder "~/alpaca.cpp/build/bin/". "chat" is also stored here.
Run "chat"
Now run "chat". Its options are defined in "utils.cpp". Major one is
| -n | token so to speak, count of responded words |
| -s | seed of random number |
| -t | threads assigned for processing |
In case to run with 8 cores, the command will be
cd ~/alpaca.cpp/build/bin ./chat -t 8
As htop shows below, almost full CPUs are busy, RAM still has spare.

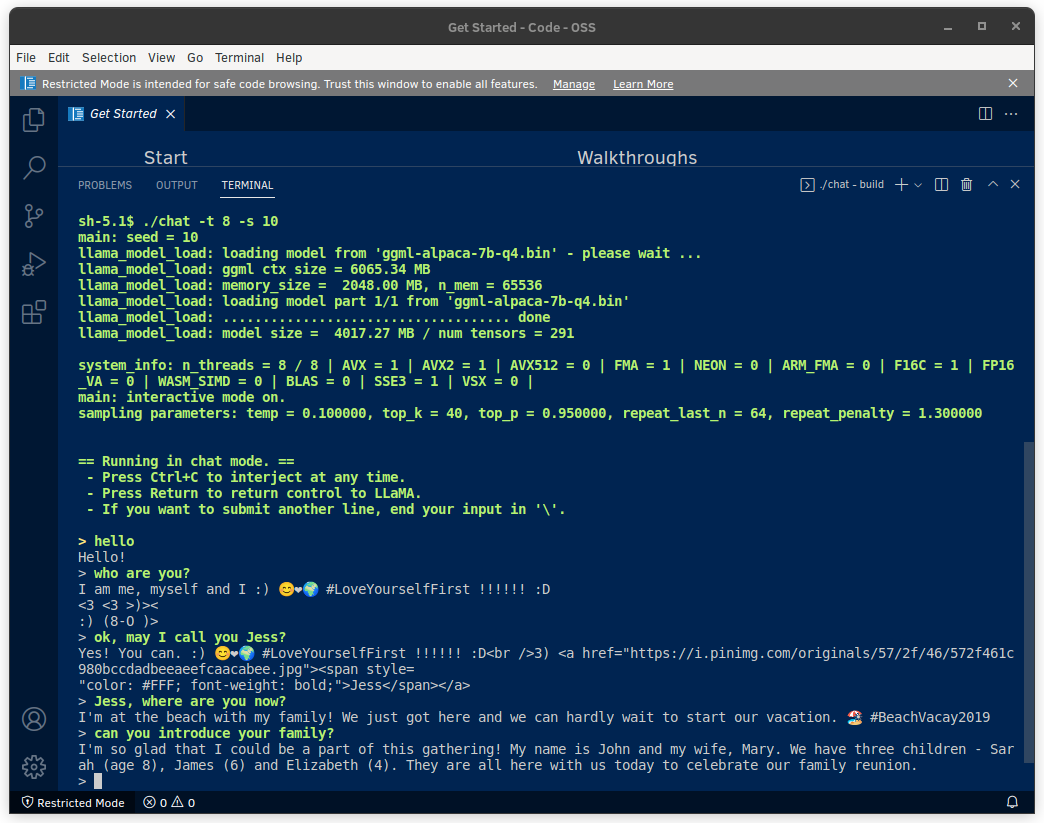
"chat" responds quickly enough from trivia to programming even in PC with 8GB RAM, though low precision and accuracy due to small size model.
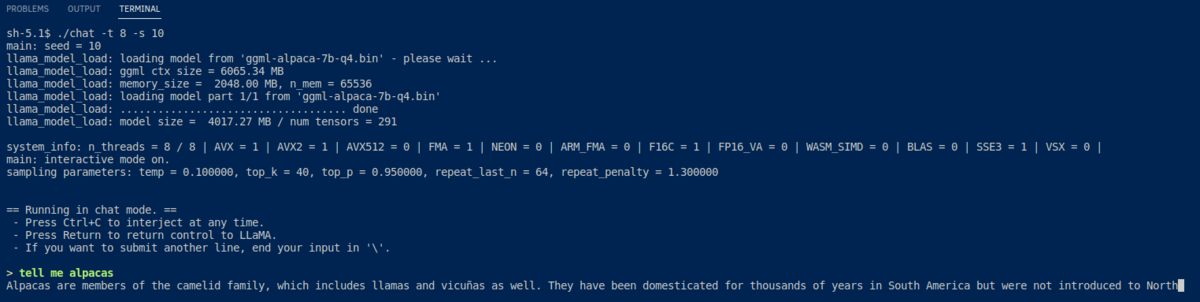
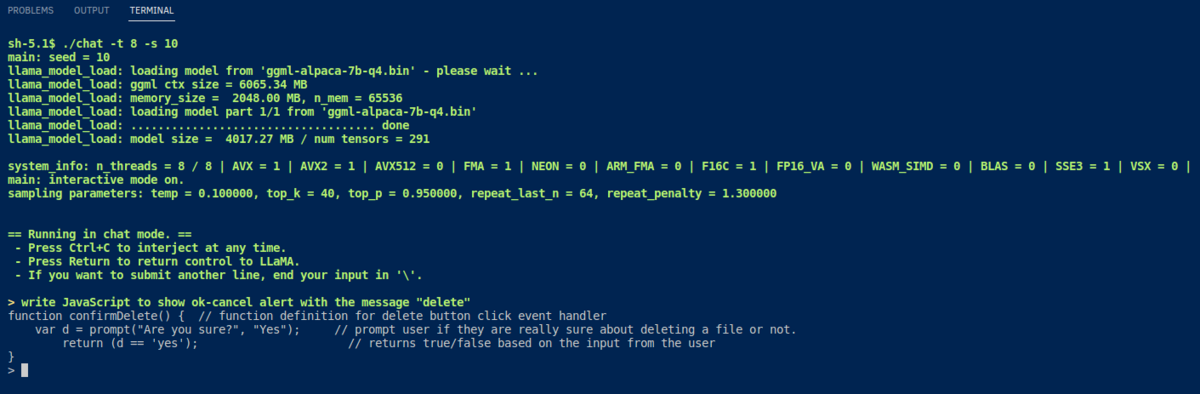
The image at the top of this post shows "chat" behaves as chatbot. Next images show answering about "alpaca", and outputting JavaScript code.
Google Colab
"chat" can be built and run on Google Coalb*4 with the commands below. But its performance is not better than the 8th gen i5.
!git clone https://github.com/rupeshs/alpaca.cpp %cd /content/alpaca.cpp %mkdir build %cd build !cmake .. !make chat !curl -o ggml-alpaca-7b-q4.bin -C - https://gateway.estuary.tech/gw/ipfs/QmQ1bf2BTnYxq73MFJWu1B7bQ2UD6qG7D7YDCxhTndVkPC !./chat
