As I delved into the overview of large-scale language models since the beginning of the year, the budding idea that emerged was that of language generation as a probability theory. There seems to exist a "true" probability model that produces appropriate words, and the idea is to bring large-scale language models closer to this true model.
Reading "Is Large Language Model a New Intelligence"*1 and found the column titled "Language Model as a Compressor.". It briefly mentioned the following:
- Encoding based on the probability distribution underlying language generation → Large-scale language models
- Encoding based on the probability distribution generating data → Data compression
- Language model = Reversible data compression for language
Then, by sheer coincidence, I stumbled upon the following blog post. This post introduces the following:
- Compression seems to correspond to general intelligence.
- Compress the corpus used to construct the encoding table and try to expand random data.
- Something resembling words was produced!
long story short, apparently compression is equivalent to general intelligence.
What if you compress a large corpus of text to build up the encoding table, then you compress your prompt and append some random data and decompress the random data, and hope it decompresses to something sensible.
It’s kind of whack but it’s hilarious to me that it produces something resembling words.
I want to cherish this serendipity. I tried the program introduced in the blog post above, and also compressed sample tweets from Twitter to see how they would be output. It's just a little weekend leisure time.
- Introduction
- Install of NLTK (Natural Language ToolKit) and NLTK corpus
- Compression and decompression
- Decompressing random data generates words?!
- Switch corpora to Twitter data
- Off-topic 1
- Off-topic 2
- Code
- Reference
Introduction
In this post, the code will be introduced selectively, focusing only on the necessary parts as needed. A complete set of code can be found at the end of this post.
Install of NLTK (Natural Language ToolKit) and NLTK corpus
NLTK*2 is a module for natural language processing and used with a corpora. This module is not pre-installed at Google Colab.
The next commands install this module and download required corpus.
!pip install nltk
nltk.download('reuters') nltk.download('brown') nltk.download('gutenberg')
Compression and decompression
LZMA (Lempel-Ziv-Markov Chain Algorithm)*3 is a compression algorithm adopted by applications like 7-Zip, and it's also a Python standard module*4 that utilizes the same algorithm source. The dictionary generated by the compression algorithm can be thought of as a probability distribution, and compression is essentially encoding based on it. When certain data is decompressed, the expectation is that some form of "language" is generated.
Define the filter at the highest compression level, and generate a compressor with it.
my_filters = [
{"id": lzma.FILTER_LZMA2, "preset": 9 | lzma.PRESET_EXTREME},
]
lzc = lzma.LZMACompressor(lzma.FORMAT_RAW, filters=my_filters)
Extract text from corpus downloded in advance, convert it as UTF8 byte code, and compress it. In the case of the "brown" corpus, convert the concatenated words separated by space because it is a list of words.
corp = nltk.corpus.reuters.raw().encode()
out1 = lzc.compress(corp)
corp = ' '.join(nltk.corpus.brown.words()).encode()
out2 = lzc.compress(corp)
corp = nltk.corpus.gutenberg.raw().encode()
out3 = lzc.compress(corp)
out_end = lzc.flush()
The encoding table is generated after decompression.
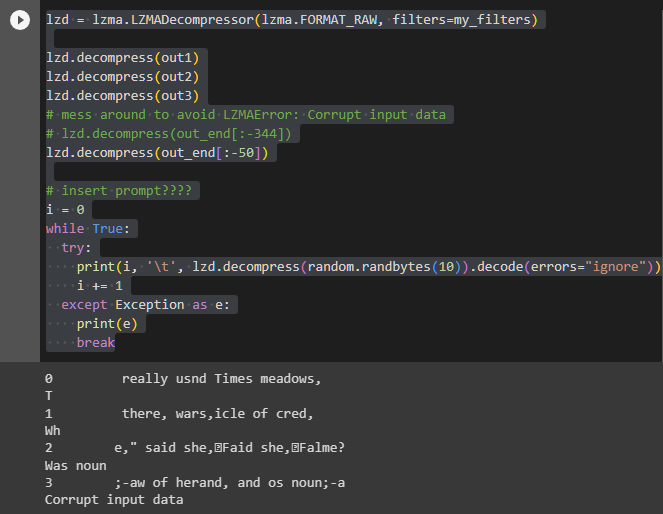
lzd.decompress(out1)
lzd.decompress(out2)
lzd.decompress(out3)
lzd.decompress(out_end[:-50])
To exclude the last 50 bytes when decompressing the final data is a measure taken in accordance with the original code. It serves as an aid to avoid errors in the subsequent random data decompression process. At this point, I have insufficient knowledge to understand the details of this mechanism.
Decompressing random data generates words?!
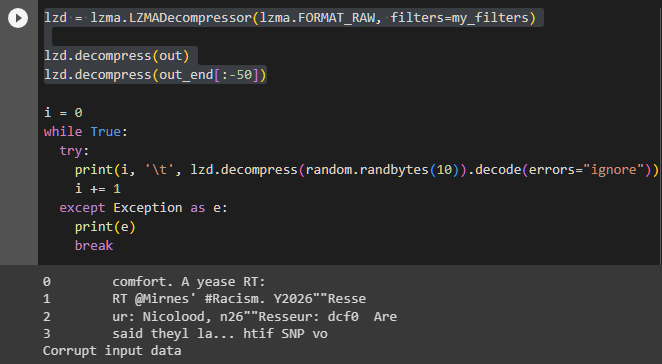
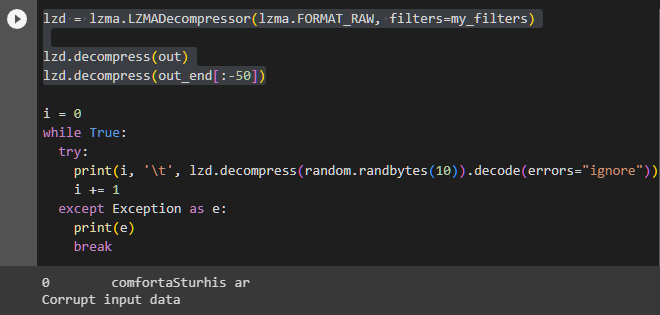
i = 0 while True: try: print(i, '\t', lzd.decompress(random.randbytes(10)).decode(errors="ignore")) i += 1 except Exception as e: print(e) break
Decode the randomly generated 10-byte data using the encoding table. It doesn't make sense, but it certainly outputs something resembling words. What's interesting is that it always starts with "really us". Could this correspond to expressions like "Dear" or "I hope you're well,"? In fact, the mentioned blog also describes that it always starts with ", and tri" every time.
Note how the start is always , and tri, usually completing it into some word.
 |
 |
 |
Switch corpora to Twitter data
Switch to another corpora, for example, consider what happens if an encoding table based on Twitter posts is generated. Download the corpora and load it from the specified path. In Google Colab, 'twitter_samples' is saved in the following folder.
/root/nltk_data/corpora/twitter_samples
Read JSON files there and extract item "text" corresponding tweet. Convert it into byte code, and compress it.
nltk.download('twitter_samples') reader = nltk.corpus.TwitterCorpusReader('/root/nltk_data/corpora/twitter_samples', '.*\.json') all_tweets = '' for tweet in reader.docs(): all_tweets += json.dumps(tweet['text'])
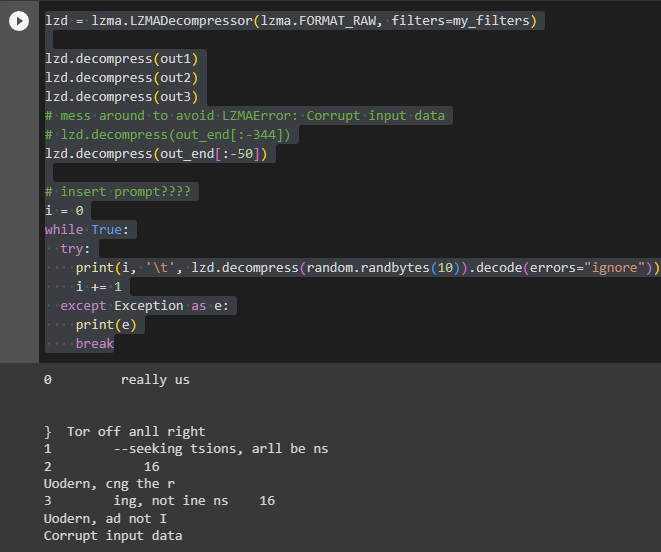
As in the previous run, when randomly generated 10-byte data is expanded, words or word-like elements are indeed generated. Moreover, it starts with the same word once again. This time, it was "comfort".
|
 |
 |
Off-topic 1
ChatGPT suggested the following titles for this blog:
- "Language Models and Probability Theory: Exploring New Knowledge and Ideas"
- "Language Models and Compression: The Intersection of AI and General Intelligence"
- "The Remarkable Potential of Language Models: Generating Words from Random Data"
- "AI and Creativity: An Experiment in Randomness and Probability Theory"
- "Weekend Experiment: An Adventure in Word Generation Using AI"
I think all of them are excellent, but I couldn't help sensing a certain degree of self-promotion, which made me ultimately summarize it in my usual straightforward manner, albeit with a hint of embarrassment.
Off-topic 2
As mentioned in a recent post *5, just because a generative AI service operates interactively does not mean that all services utilizing language models need to be that way, nor do they necessarily need to be universally applicable.
Is there anything meaningful that can be done with a small-scale language model that can be trained in Llama2.c or a configuration that operates in very common and reasonable environments like this compression algorithm we have now?
Taking into consideration the premise of not just being "okay to make mistakes" but also "okay not to understand," what potential applications might exist?
Code
Reference
twitter.comthis is wild — kNN using a gzip-based distance metric outperforms BERT and other neural methods for OOD sentence classification
— Riley Goodside (@goodside) 2023年7月13日
intuition: 2 texts similar if cat-ing one to the other barely increases gzip size
no training, no tuning, no params — this is the entire algorithm: https://t.co/7mLIRlX48N pic.twitter.com/IWe402RGgn
")