年初から大規模言語モデルの概要に触れていくうちに、芽生え始めたアイデアが確率論としての言語生成だった。適切な言葉が出力される「真の」確率モデルが存在しており、大規模言語モデルを真のモデルへ近づけていくようなイメージだ。
書籍『大規模言語モデルは新たな知能か』*1には、「圧縮機としての言語モデル」というコラムが掲載されていた。手短に記せば、次のようなことが書かれていた。
そして偶然たどり着いたのが、次のブログ投稿だった。この投稿で紹介されているのは、次のようなことだ。
long story short, apparently compression is equivalent to general intelligence.
What if you compress a large corpus of text to build up the encoding table, then you compress your prompt and append some random data and decompress the random data, and hope it decompresses to something sensible.
It’s kind of whack but it’s hilarious to me that it produces something resembling words.
この巡り合わせは大切にしたい。先のブログ投稿で紹介されているプログラムを試すとともに、Twitterからのサンプル投稿を圧縮して、どのように出力されるのかも確認してみた。ちょっとした週末の余暇だ。
- はじめに
- NLTK (Natural Language ToolKit)、NLTKコーパスの導入
- 圧縮と展開
- ランダム・データの展開→言葉の生成!?
- コーパスをTwitterに変える
- 余談1
- 余談2
- コード
- 参照
はじめに
コードは、必要に応じて、必要な箇所だけを紹介していく。一連のコードひとまとまりは、この投稿末尾に掲載している。
NLTK (Natural Language ToolKit)、NLTKコーパスの導入
NLTK*2は自然言語処理のためのモジュールだ。コーパスの操作に用いる。検証環境にはGoogle Colabを利用した。Google ColabにはNLTKが導入されていないので、インストールしておく。
!pip install nltk
nltk.download('reuters') nltk.download('brown') nltk.download('gutenberg')
圧縮と展開
LZMA (Lempel-Ziv-Markov chain-Algorithm)*3は7-Zipなどで採用されている圧縮アルゴリズムであり、同アルゴリズムを採用しているPython標準モジュールだ*4。圧縮アルゴリズムで生成される辞書が、言うなれば確率分布であり、それによる圧縮が符号化だ。あるデータが展開されることで、何らかの「言葉」が生成されることを期待している。
まず圧縮に用いる圧縮器を生成する。そのフィルタとして最高レベルの圧縮を定義している。
my_filters = [
{"id": lzma.FILTER_LZMA2, "preset": 9 | lzma.PRESET_EXTREME},
]
lzc = lzma.LZMACompressor(lzma.FORMAT_RAW, filters=my_filters)
先にダウンロードしておいたコーパスからテキストを抽出し、UTF8のバイトコードに変換したものを圧縮している。コーパス"brown"は単語のリストなので、半角スペースで単語を連結したものをバイトコードへ変換している。
corp = nltk.corpus.reuters.raw().encode()
out1 = lzc.compress(corp)
corp = ' '.join(nltk.corpus.brown.words()).encode()
out2 = lzc.compress(corp)
corp = nltk.corpus.gutenberg.raw().encode()
out3 = lzc.compress(corp)
out_end = lzc.flush()
これらを展開することによって、アルゴリズムによってエンコード表が生成されている。
lzd.decompress(out1)
lzd.decompress(out2)
lzd.decompress(out3)
lzd.decompress(out_end[:-50])
最後のデータを展開するのに、末尾50バイトを除外しているのは、オリジナルのコードに倣った措置だ。後続のランダム・データの展開処理において、エラーを回避するための一助になっている。この仕組みの詳細について、現時点では勉強不足で、私はまだ何も把握していない。
ランダム・データの展開→言葉の生成!?
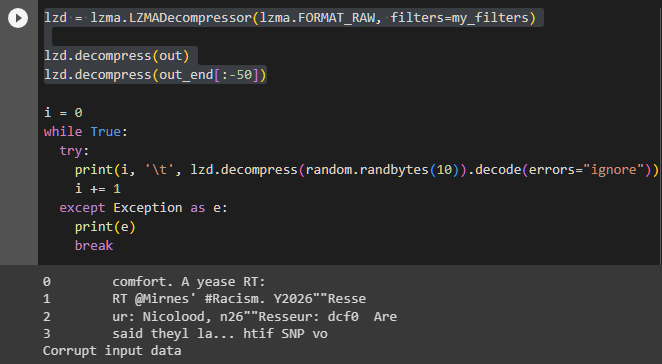
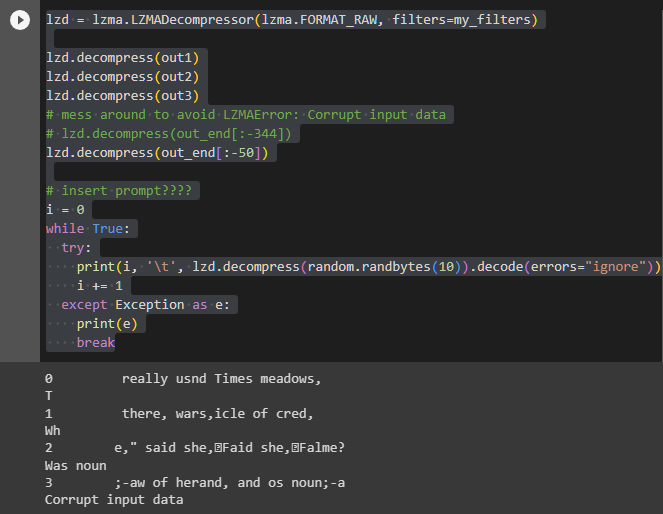
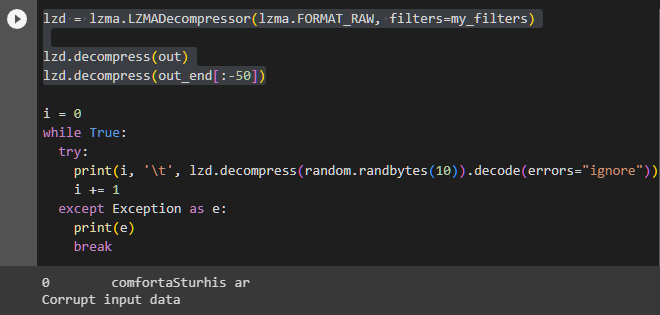
i = 0 while True: try: print(i, '\t', lzd.decompress(random.randbytes(10)).decode(errors="ignore")) i += 1 except Exception as e: print(e) break
ランダムに生成した10バイトのデータを、エンコード表で展開してみる。意味は通らないが、確かに言葉らしきものが出力されている。面白いのは、必ず「really us」で始まることだ。「拝啓」や「お疲れ様です」のような感じの表現に相当するのだろうか。実際、件のブログでも毎回「, and tri」で始まっていることに言及している。
Note how the start is always , and tri, usually completing it into some word.
 |
 |
 |
コーパスをTwitterに変える
そこで思いついたのが、コーパスを変えてみることだ。例えばTwitterの投稿を元にエンコード表を生成したらどうなるだろうか。
目的のコーパスをダウンロードしたら、パスを指定して読み込む。Google Colabの場合、次のフォルダにダウンロードされる。
/root/nltk_data/corpora/twitter_samples
ここに収録されているJSONファイルを参照し、Tweet本文に相当する項目"text"の文字列を抽出する。これをバイトコードへ変換し、圧縮するのだ。
nltk.download('twitter_samples') reader = nltk.corpus.TwitterCorpusReader('/root/nltk_data/corpora/twitter_samples', '.*\.json') all_tweets = '' for tweet in reader.docs(): all_tweets += json.dumps(tweet['text'])
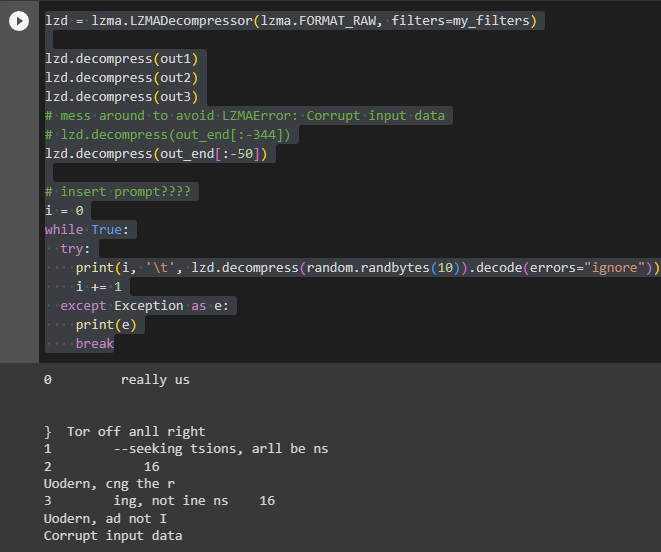
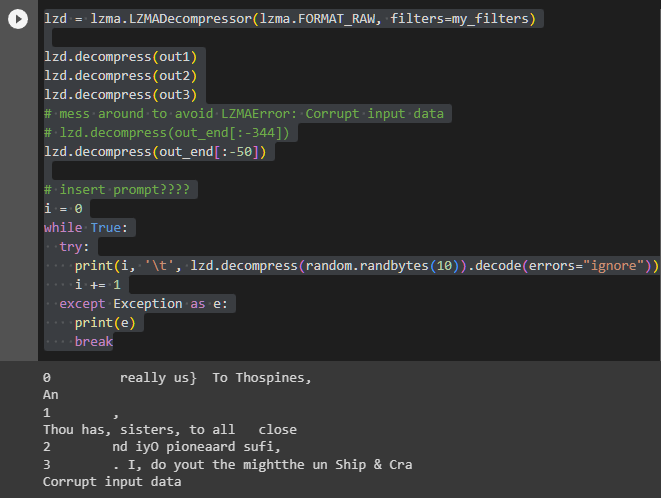
同様に、ランダムに生成した10バイトのデータを展開すると、やはり言葉らしきものが出力される。そしてやはり、同じ言葉で始まるのだ。今回は「comfort」だった。
|
 |
 |
余談1
このブログについて、ChatGPTは次のようなタイトルを発案してくれた。
- "言語モデルと確率論:新たな知識とアイデアの探求"
- "言語モデルと圧縮:AIと一般的知能の接点"
- "言語モデルの驚くべき可能性:ランダムデータからの言葉生成"
- "AIと創造性:ランダム性と確率論の実験"
- "週末の実験:AIを使って言葉を生み出す冒険"
どれもばっちりだと思うのだが、気恥ずかしさと同時に、いわゆる「煽り」のような印象も察してしまい、結局いつも通り、ありのままを要約してしまうのだった。
余談2
先日の投稿でも触れた*5ように、生成AIサービスが対話形式だからと言って、言語モデルを用いたすべてのサービスがそうである必要はないし、汎用的である必要もないはずなのだ。
Llama2.cでトレーニングできるような小規模な言語モデル、あるいは今回の圧縮アルゴリズムのように、ごく一般的、リーズナブルな環境でも動作する構成で、何か有意義なことができないか、という考えがちらつくことが多い。
「間違えてもOK」を通り越して、「意味が分からなくてもOK」という前提も加味して、どのような応用があるだろうか。
コード
参照
twitter.comthis is wild — kNN using a gzip-based distance metric outperforms BERT and other neural methods for OOD sentence classification
— Riley Goodside (@goodside) July 13, 2023
intuition: 2 texts similar if cat-ing one to the other barely increases gzip size
no training, no tuning, no params — this is the entire algorithm: https://t.co/7mLIRlX48N pic.twitter.com/IWe402RGgn