This is the rewriting of the last post*1 especially for Windows user. Although GitHub providing source code introduces building with CMake*2, this post uses Visual Studio instead.
CPU for evaluation is Intel Core i7-6700T. This is the relatively slower model with low-energy consumption. responses are not smooth, but output performance is enough sufficient without being waited.
It is realized that the key for performance and accuracy is the size of model.
Downloading source code and model
Downloading source code from GitHub, and extract it to any folder, example the the next folder. This folder is called "working folder" in this post.
G:\work\alpaca\
And following the instruction there*3, download Alpaca 7B model. The size of this model is 4GB. GitHub introduces following methods to download it. BitTorrent was used in this post.
Building execution file
Building execution file with Visual Studio. Version in this post is "Visual Studio 2022 Version 17.5.3".
Run Visual Studio
- Open the working folder in Explorer, open the context menu with right clicking
- Select "Open Visual Studio" from the menu
- Select "CMake settings editor"
 |
 |
CMake configuration
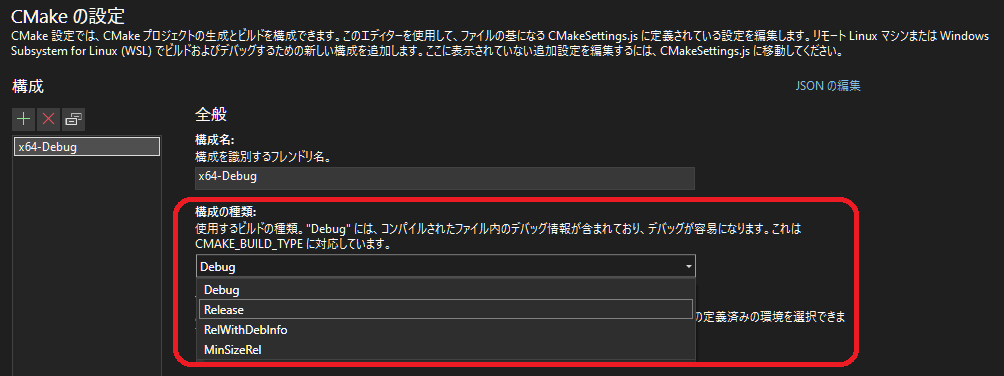
- Open "CMake Settings"
- Select "Release" at "Configuration type"
Build
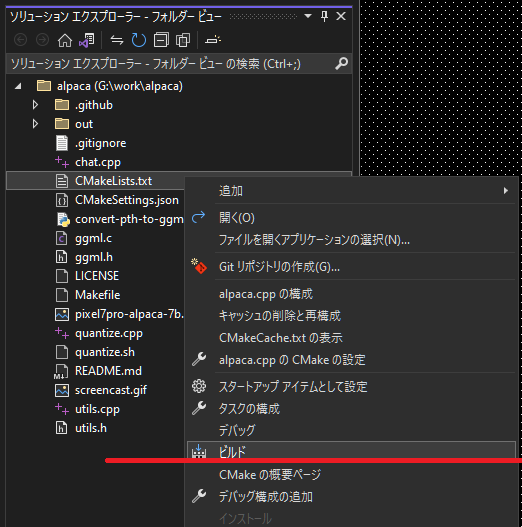
- Right click "CMakeLists.txt" at solution explorer, and open context menu
- Select "Build", then new CMake is generated
- Select "Build" again, then release build of chat.exe is generated
 |
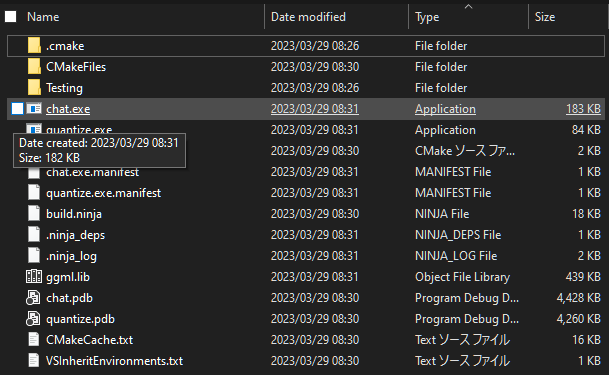 |
After the 2nd build, chat.exe is generated in the next folder.
G:\work\alpaca\out\build\x64-Debug\
Run chat.exe
Save chat.exe and Alpaca 7B model in a common folder, example the next folder in this post.
P:\myapp\alpaca\
chat.exe prepares command options as
| -n | the number of token in other words, amount of responds word. |
| -s | seed of random number |
| -t | the number of thread |
The next command assignes 8 CPU cores for chat.exe.
cd P:\myapp\alpaca\ .\chat.exe -t 8
The next image shows the usage of CPU and RAM during prediction. CPU is almost busy, but RAM still has spare.

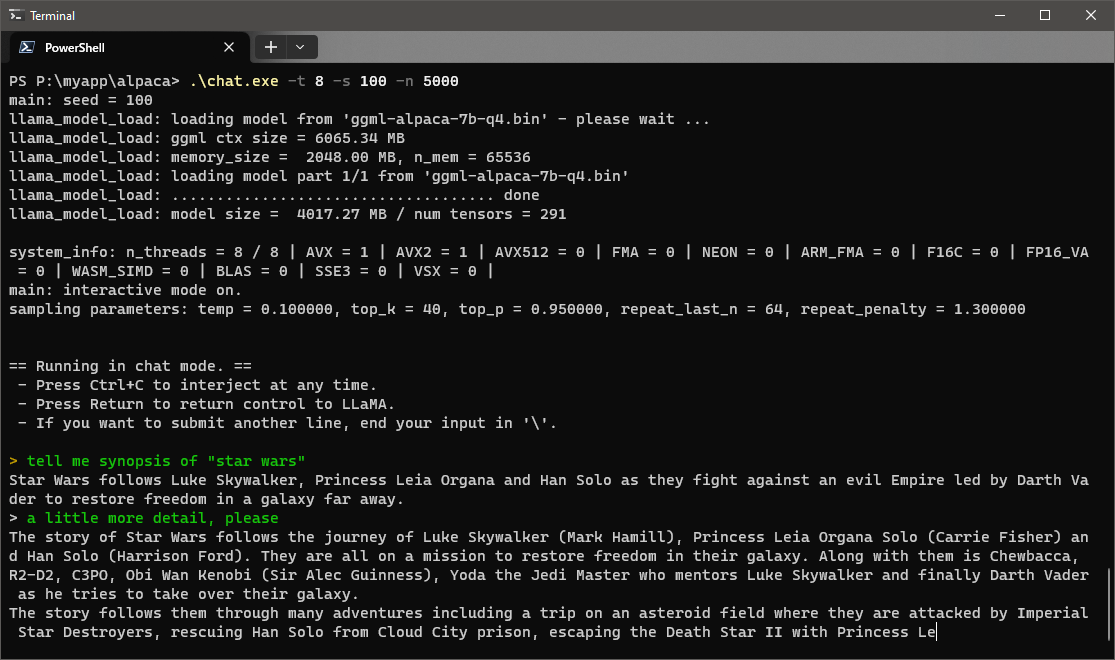
Asking synopsis of "Star Wars", chat.exe answered as following images. Although output is inaccurate and inconsistent due to size of the model, even the 6th gen Intel core can output such amount of responses without waiting.
|
 |