今回の投稿は、先日の投稿*1のWindows編だ。インストール環境がLinuxからWindowsへ変わる以外、使用するプログラムとモデルは、前回と変わらない。
Windowsへのインストールに際し、ソースコード提供元のGitHubではCMake*2を用いた方法を紹介しているが、この投稿ではVisual Studioを使用する。
検証環境のCPUはIntel Core i7-6700Tだ。第6世代コアでも、低消費電力で、動作周波数も低いモデルだ。さすがにスラスラと回答が出力されるようなことはないのだが、それでも待たされることなく、十分実用レベルのパフォーマンスで動作している。
パフォーマンスだけでなく出力の精度を含め、やはりポイントは、モデルのサイズと精度次第なのだと実感した。
ソースとモデルのダウンロード
ソースコードを、その提供元のGitHubからダウンロードする。ダウンロードしたソースコードを適当なフォルダへ展開する。この投稿では、次のフォルダに展開している。このフォルダを「作業フォルダ」と呼ぶことにする。
G:\work\alpaca\
さらに掲載されている指示*3に従って、Alpaca 7Bモデルもダウンロードする。
Alpaca 7Bモデルのサイズは4GBだ。このサイズのファイルをダウンロードするために、GitHubページでは、次の方法が提示されている。
各自お好みの方法でダウンロードすればよいと思う。私の場合、PCへのダウンロードにはBitTorrentを用いた。
実行ファイルの生成
この投稿では、実行ファイルの生成にVisual Studioを用いる。使用しているバージョンは、「Visual Studio 2022 Version 17.5.3」だ。
- エクスプローラで作業フォルダを開き、右クリックでコンテキスト・メニューを表示する。
- メニューから「Visual Studioで開く」を選択する。
- Visual Studioが起動する
- Visual Studioにて「CMake設定エディターを開く」を選択する。
 |
 |
CMakeの設定
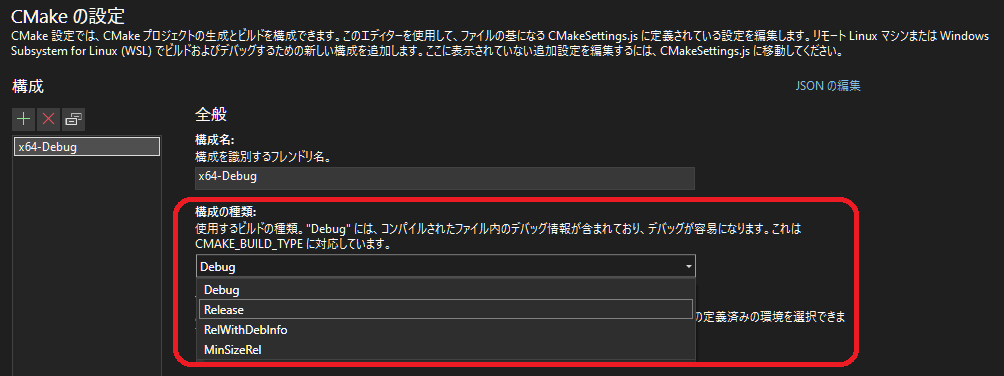
- 「CMakeの設定」が表示される
- 「CMakeの設定」にて「構成の種類」から「Release」を選択する。
ビルド
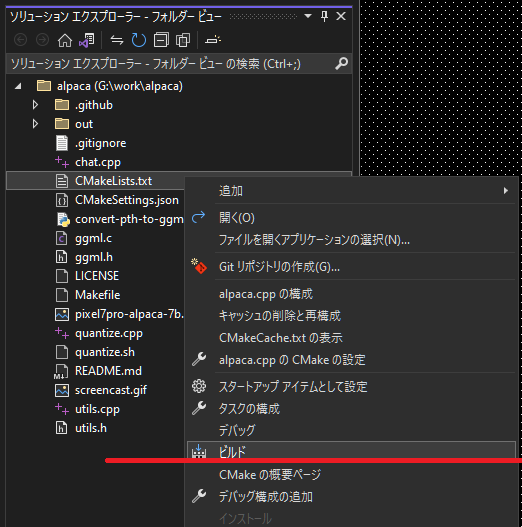
- 「ソリューションエクスプローラー」にて「CMakeLists.txt」を右クリックし、コンテキスト・メニューを表示する。
- メニューから「ビルド」を選択する→新しいCMakeが作成される
- メニューから「ビルド」を再び選択する→chat.exeのリリースビルドが生成される
 |
 |
2度目のビルドで、chat.exeのリリース・ビルドが次のフォルダに出力されている。
G:\work\alpaca\out\build\x64-Debug\
chat.exeの実行
chat.exeとAlpaca 7Bモデルを同一のフォルダへ保存する。この投稿では、次のフォルダに保存している。
P:\myapp\alpaca\
chat.exeを実行する前に、そのオプションの一部について触れておく。
| -n | トークン数token 言うなれば、返答の単語数 |
| -s | 乱数シード |
| -t | 処理スレッド数 |
もし8コア搭載CPUの全コアを用いて"chat"を動作させるなら、コマンドは次のようになる。
cd P:\myapp\alpaca\ .\chat.exe -t 8
問いかけに対する推論を開始すると、CPU並びにRAMの使用状況は次のようになる。CPUはほぼ全力だが、RAMには余裕があることが確認できる。

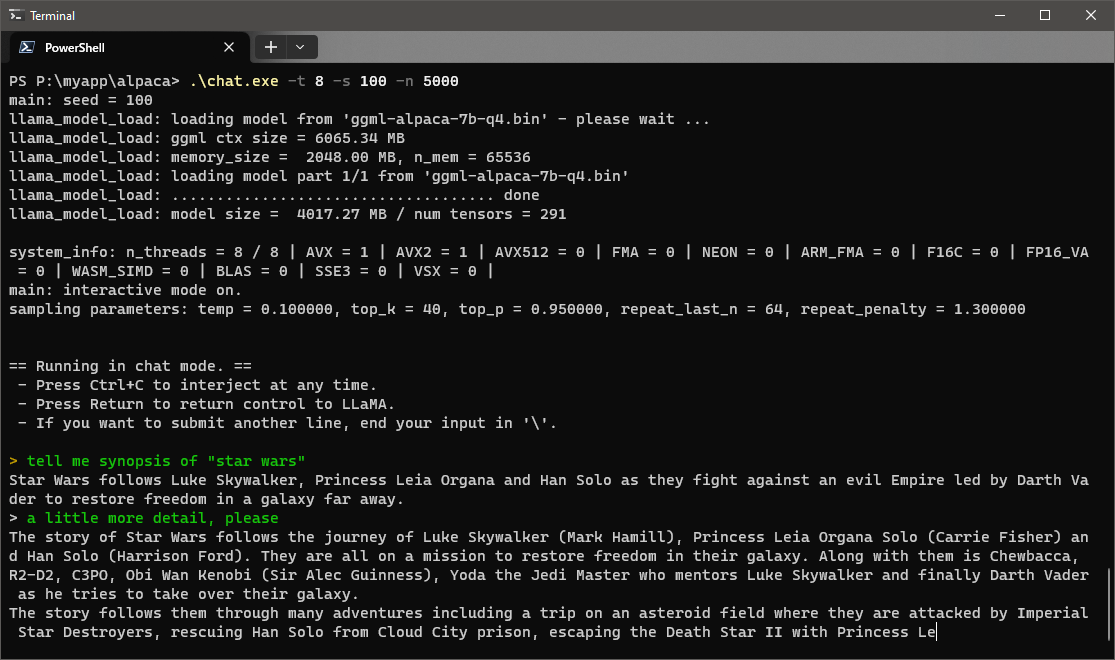
次の画面は、映画『STAR WARS』のあらすじ、その詳細を問いかけてみたものだ。モデルの小ささに伴う精度、不整合や正確さには目をつぶるとしても、第6世代Coreでも、これだけの分量を待たせることなく出力してくれる。
|
 |