
03:06AM
室温、30.4度
湿度、H1
かなり過ごしやすくなった。
AI
karpathy/llama2.c
格闘中。
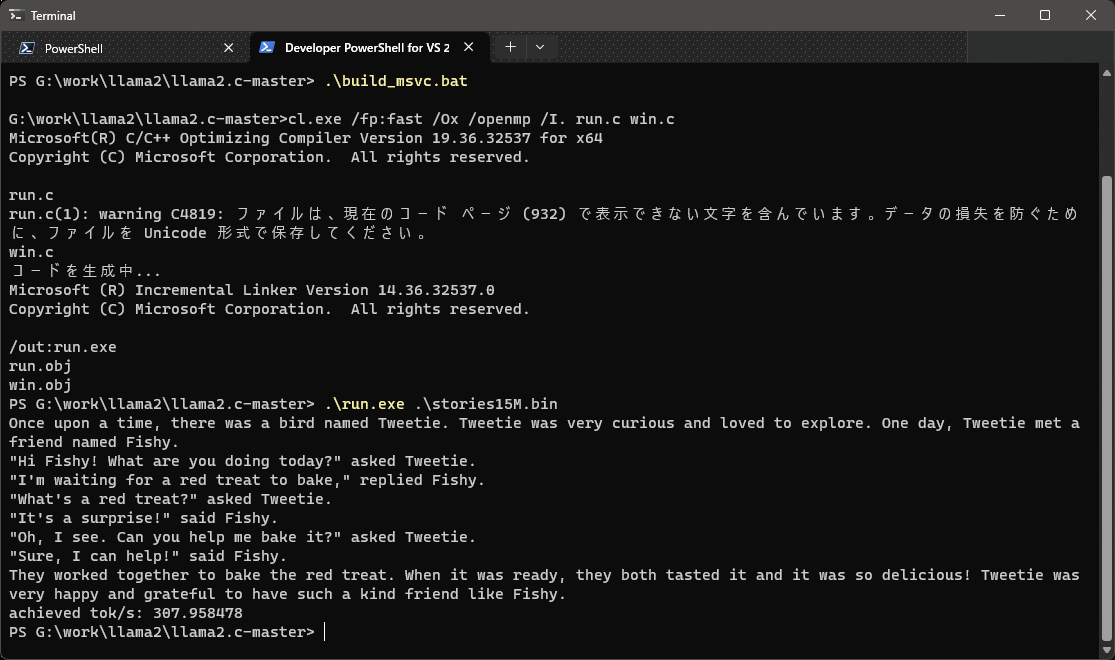 |
 |
Windowsでは推論を簡単に実行できる。batファイルを呼び出すだけで、並列処理対応の実行ファイルを生成できる。推論のパフォーマンスは、第6世代Intel Core i7で秒間300トークン程度。
”python tinystories.py pretokenize”まではスムーズに実行できる。しかしvocab_sizeを指定したり、トレーニングまで実行しようとすると、さまざまに手を加える必要がある。
Clear Linuxでも、全てをスムーズに実行というわけにはいかない。それなりに指定外の作業を行う必要がある。
実行ファイルの生成は、次のように指定すると並列処理対応の実行ファイルを生成できる。第7世代Intel Core i5で秒間300トークン程度。
make runomp
以下の処理を実行するためには、sentencepieceを導入する必要がある。"pretokenize"完了までに30分ほどを要した。
python tinystories.py train_vocab --vocab_size=4096 python tinystories.py pretokenize --vocab_size=4096
sentencepieceの導入について、ビルドはGitHubの指示通りに対応すれば問題ない。問題なのは、Clear Linuxの標準とは異なる場所にライブラリが格納されることだ。このパスを環境変数に設定する必要がある。
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib64
ここで次のコマンドを実行するのだが、またしてもtorch.compileに阻まれる。Python 3.11以上に対応していないのだ。
python train.py --vocab_source=custom --vocab_size=4096
Train.pyの71、73行目を次のように編集する。
device = "cpu" compile = False
RAM=8GBの場合、swapも作っておく必要がある。
sudo dd if=/dev/zero of=~/work/llama2.c/swap.img bs=1M count=8096 sudo chown 0:0 ~/work/llama2.c/swap.img sudo chmod 600 ~/work/llama2.c/swap.img sudo mkswap ~/work/llama2.c/swap.img sudo swapon ~/work/llama2.c/swap.img
これでひとまずtorch.compileの問題は避けられる。40分ほどを要した。今日はここまで。
