4月6日の1%超の下落を記録して以降、日本市場は変動の少ない、凪のような状態が続いている。このような時、できる人たちは次の相場に備えて静かに行動しているのだろう。
ひふみ投信はボクシングで言うところのクリンチと称し、マーケットにしがみつくように追従しながら、21年型の構成銘柄への入れ替えを進めているという。海外投資家も、円安を背景に有料バリュー銘柄を静かに買い進めているようだ。
私はと言えば、ノルウェー政府年金基金SWF (Sovereign Wealth Funds)の資料を参照しながら、コロナ前後での構成銘柄の変化を調べていた。このSWFは世界中に投資しており、日本企業にも2019~20年の間で約1500社の株式を保有している。
調査を通じて気付いたのは、この程度のデータ操作はR、特にデータ型tibbleの操作練習にちょうど良いということだった。
この投稿では、資料を読み進めながら、tibbleの操作を説明していく。
資料は投稿末尾のリンク先よりダウンロードできる。この投稿では、次の資料を参照している。どちらもExcelファイルをダウンロードしている。
- Total holdings sorted by country (2019 / Equities)
- Total holdings sorted by country (2020 / Equities)
おことわり
効率的に分析するには、
- 業種分析
- 業種内の企業分析
- 単一企業分析
の様にドリルダウンしていくのが本来のやり方なのだが、この投稿ではtibble操作が容易、簡潔な順に進行している。
またtibbleとパイプの特性について馴染みのない人は、先に次の投稿に目を通してほしい。
impsbl.hatenablog.jp
事前準備
ダウンロードしたファイルに対して、次の作業を行う。
- ダウンロードしたExcelファイルを開き、新しく”Japan”というタブを作成する。
- タブ”Holdings Report”の”Country”列で、"Japan"をフィルタする。
- 抽出されたデータを全選択し、"Japan"タブへ貼り付ける。
- Excel上のデータ
| Region | 投資対象地域 |
| Country | 投資対象国 |
| Name | 投資対象企業名 |
| Industry | 投資対象業種 |
| Market Value(NOK) | 市場価値 ノルウェー・クローネ換算 |
| Market Value(USD) | 市場価値 米ドル換算 |
| Voting | 議決権比率 (%) |
| Ownership | 持ち分比率(%) |
ライブラリ、Excelの読み込み、データのtibble化
Tidyverseライブラリを参照し、Excelファイルを読み込む。
Excelファイルを年度ごとに読込、それぞれをtibbleへ変換する。
🔎R code
library(tidyverse) #read Excel as tibble df2019 = read_excel("EQ_2019_Country.xlsx", sheet = "Japan") df2020 = read_excel("EQ_2020_Country.xlsx", sheet = "Japan") master2019 = as_tibble(df2019) master2020 = as_tibble(df2020)
2019~2020年の構成銘柄の変化
inner_join 表の内部結合:持越し銘柄の確認
2019、20年度のデータから、共通の会社名を絞り込めば、持越し銘柄を確認することができる。
”inner_join”を用いて、会社名をキーに、両年度のデータを単一のデータに統合している。
出力より、共通の列名のうち20年のデータが".x"、19年のデータが".y"として統合されているのが分かる。
🔎R code
carry_over = inner_join(master2020, master2019, by="Name") carry_over
🔎Output

arrange tibbleの新規作成、ソート:持越し銘柄の変化
持越し銘柄の価値、持ち分比率の変化を知りたい。
これを昇順、降順で表示することで増やした銘柄、減らした銘柄が分かる。
外貨換算レートの影響を無視するため、ソートは持ち分比率を基準とした。
このデータを示すtibbleを、新たに作成し、表示する。
🔎R code
#carry over - difference carry_over_difference = tibble( stock.name = carry_over$Name, difference.value = carry_over$`Market Value(USD).x` - carry_over$`Market Value(USD).y`, difference.ownership = carry_over$Ownership.x - carry_over$Ownership.y ) #carry over - decrease carry_over_difference %>% arrange(difference.ownership) #carry over - increase carry_over_difference %>% arrange(desc(difference.ownership))
🔎Output


anti_join 表の排他結合:新規組入れ銘柄、売却銘柄
2020年の新規組入れされた銘柄を知るには、2020年のデータに存在するが、2019年のデータには存在しない企業を探せばよい。2020年に持越しされなかった銘柄、つまり2019年に売却された銘柄を知るには、逆の企業を探せばよい。
これらは”anti_join”を用いて、会社名をキーとする共通の作業として対応できる。
一つ注意しなければならないのは、名称の変化だ。今回のデータでは19年度にAGC(旭硝子)が売却され、20年度に新規組入れされている。これはデータ名の相違によるものだ。このようなケースを未然に防ぐため、本来であれば前処理としてクレンジングしなければならないのだが、今回は無視している。
🔎R code
#new entry in 2020 anti_join(master2020, master2019, by="Name") #dropped from 2020 anti_join(master2019, master2020, by="Name")
🔎Output


2019~2020年の構成業種の変化
本来であれば、個々の銘柄の変化を調べる前に、業種の変化を調べるべきだろう。そこから特定業種に的を絞り、その構成企業を調べる、と言ったドリルダウンのやり方の方が効率が良い。
データの特性上、業種ごとの変化を調べるには、業種単位でデータを集計する必要があり、その準備に一手間かかる。
group_by, summarise_at グループごとの集計:業種ごとの集計
業種ごとに市場価値(USD)、持ち分比率を集計した表を作成する。
ここでも19、20年度ごとにデータを分けておく。
| 業種ごとのグループ化 | group_by |
| 対象項目の特定 適用する関数の指定 |
summarise_at |
🔎R code
industry2019 = df2019 %>% group_by(Industry) %>% summarise_at( vars( `Market Value(USD)`, Ownership), sum) industry2020 = df2020 %>% group_by(Industry) %>% summarise_at( vars( `Market Value(USD)`, Ownership), sum)
出来上がったtibbleをもとに、業種の変化などを調べていくやり方は、銘柄分析の処理構造と同じだ。例えば、業種ごとの変化を調べるには、全結合した表から、差分を示すtibbleを出力する。
🔎R code
industry_carry_over = inner_join(industry2020, industry2019, by="Industry") industry_difference = tibble( industry.name = industry_carry_over$Industry, difference.value = industry_carry_over$`Market Value(USD).x` - industry_carry_over$`Market Value(USD).y`, difference.ownership = industry_carry_over$Ownership.x - industry_carry_over$Ownership.y ) industry_difference
🔎Output

出力されたデータを見ると、次のことが分かる。
- Industrials(工業)の価値が増えたが、持ち分比率が落ちた。
- 資産価値が上昇し、一部を売却したのかもしれない。→リバランス?
- Consumer Servicesは価値も、持ち分比率も落ちた。
- 新型コロナ感染に伴う売却の影響?
full_join 表の全結合、データの絞り込み:業種による企業の絞り込み
資産価値、持ち分比率が落ちたConsumer Servicesを深堀してみる。
特定業種に含まれる企業を絞り込むに際し、まず20、19年の全データを結合する必要がある。業種の変化を企業レベルで確認するに際し、新規組み入れ銘柄と売却銘柄を考慮する必要があるからだ。全結合したデータを基に、業種で絞り込んだデータを抽出することになる。
やはりここでも処理構造は同じだ。元になるデータのまとまりをtibbleとして生成し、必要な差分を出力しながらデータを観察することになる。
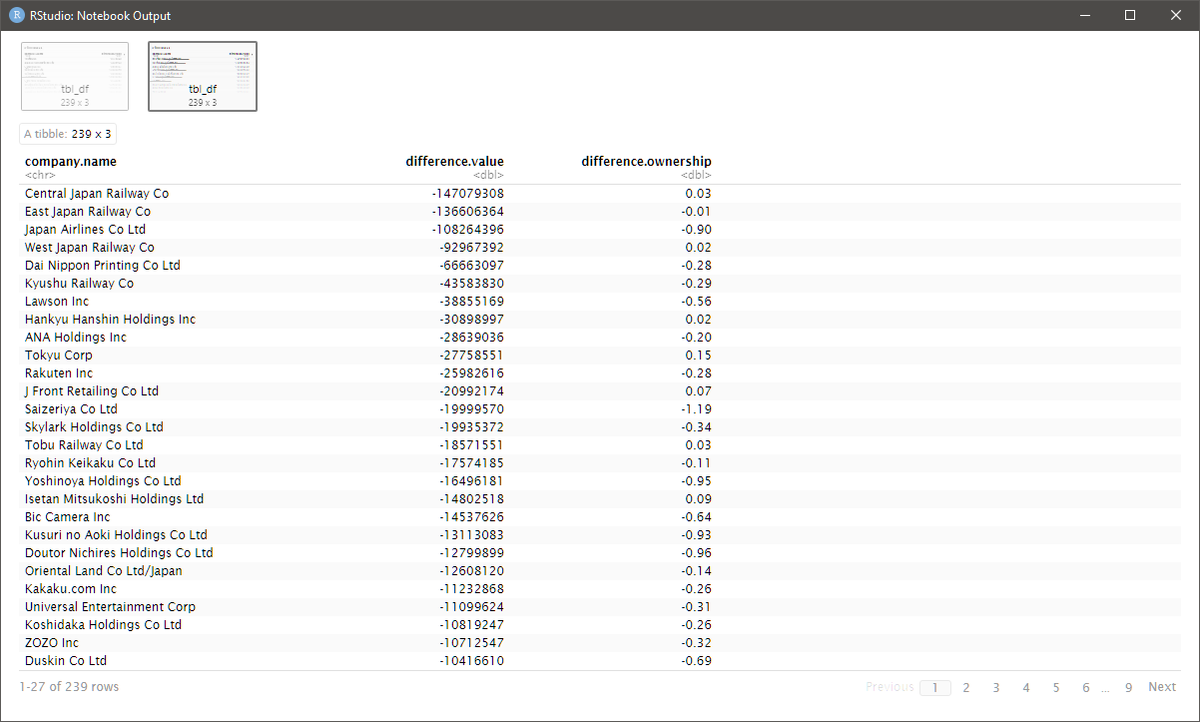
データを確認すると、JRやJALなど旅行関連銘柄や、外食関連銘柄が大きくポジションから外されているのが分かる。
🔎R code
full_set = full_join(master2020, master2019, by="Name") consumer_service = full_set %>% filter(Industry.x == "Consumer Services") consumer_service_difference = tibble( company.name = consumer_service$Name, difference.value = consumer_service$`Market Value(USD).x` - consumer_service$`Market Value(USD).y`, difference.ownership = consumer_service$Ownership.x - consumer_service$Ownership.y ) consumer_service_difference %>% arrange(difference.value) consumer_service_difference %>% arrange(difference.ownership)
🔎Output

コード全文
🔎R code
library(tidyverse) #read Excel as tibble df2019 = read_excel("EQ_2019_Country.xlsx", sheet = "Japan") df2020 = read_excel("EQ_2020_Country.xlsx", sheet = "Japan") master2019 = as_tibble(df2019) master2020 = as_tibble(df2020) #carry over carry_over = inner_join(master2020, master2019, by="Name") carry_over #carry over - difference carry_over_difference = tibble( stock.name = carry_over$Name, difference.value = carry_over$`Market Value(USD).x` - carry_over$`Market Value(USD).y`, difference.ownership = carry_over$Ownership.x - carry_over$Ownership.y ) #carry over - decrease carry_over_difference %>% arrange(difference.ownership) #carry over - increase carry_over_difference %>% arrange(desc(difference.ownership)) #new entry in 2020 anti_join(master2020, master2019, by="Name") #dropped from 2020 anti_join(master2019, master2020, by="Name") #industry industry2019 = df2019 %>% group_by(Industry) %>% summarise_at( vars( `Market Value(USD)`, Ownership), sum) industry2020 = df2020 %>% group_by(Industry) %>% summarise_at( vars( `Market Value(USD)`, Ownership), sum) industry_carry_over = inner_join(industry2020, industry2019, by="Industry") industry_difference = tibble( industry.name = industry_carry_over$Industry, difference.value = industry_carry_over$`Market Value(USD).x` - industry_carry_over$`Market Value(USD).y`, difference.ownership = industry_carry_over$Ownership.x - industry_carry_over$Ownership.y ) industry_difference #drill down full_set = full_join(master2020, master2019, by="Name") consumer_service = full_set %>% filter(Industry.x == "Consumer Services") consumer_service_difference = tibble( company.name = consumer_service$Name, difference.value = consumer_service$`Market Value(USD).x` - consumer_service$`Market Value(USD).y`, difference.ownership = consumer_service$Ownership.x - consumer_service$Ownership.y ) consumer_service_difference %>% arrange(difference.value) consumer_service_difference %>% arrange(difference.ownership)