TidyverseというRパッケージのコレクションがある。私はこれまで、定番パッケージ群を一度に導入できる便利セット、的に捉えていたのだが、これは大きな誤りで、損失を伴う勘違いだった。ただパッケージを集めただけではなく、その利用の前提となる思想を伴うものだった。それはデータ整形から分析までの背景にある、次のアイデアだ。
- Tidy Dataというデータのあり方
- Tidy tools manifestoという、ツールを使う上での考え
加えて、これらのアイデアは、Rを学び、利用し始めるに際しても有効に機能する。優しく理解できる要素もあり、学習効率も良い方法に通じているからだ。これまで投稿した「Rの初歩」に加えてしかるべき話題だし、過去に投稿した非効率な方法を更新する意味でも、有意義な話題だと考えた。
パッケージ
Tidyverseはパッケージ群だ。インストールするだけで、Tidy Data、Tidy Toolsを用いた”Tidyなやり方”を実践できるパッケージが網羅されている。主要なところでは、次のパッケージが含まれている。
| dplyr | データ操作 |
| ggplot2 | データ可視化 |
| tibble | データ型、tibbleの対応 |
| tidyr | Tidy data形式への変形 |
その他にweb API、スクレイピング、関数型プログラミング、多用なデータ入出力に対応するパッケージも網羅されている。コードの冒頭に次の1行を加えるだけで、含まれる全パッケージを利用できる。パッケージを個別にロードする必要はない。
library(tidyverse)
Tidyなやり方
Tidy Data
Tidyverseが前提としているデータのあり方がTidy Dataだ。それは次のように定義されている。
1. Each variable forms a column.
2. Each observation forms a row.
3. Each type of observational unit forms a table.
Tidy data • tidyr
単一の変数名が1行に、単一の観測が1行に、それらで構成される観測単位として表になる、といった具合だ。
tibble
Tidy Dataとして整形されたデータは、Tidyverseではtibbleとして処理される。tibbleは「modern reimagining of the data.frame」とされている。data.frameとの違いとして際立っているのは、どう処理してもtibbleはtibbleであり続けることだろう。例えば、次のコードと出力結果だ。
🔎R code and output
> head(mtcars) mpg cyl disp hp drat wt qsec vs am gear carb Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4 Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1 Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1 Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2 Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1 > > my_df = mtcars > my_df[, 1] [1] 21.0 21.0 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 17.8 16.4 17.3 15.2 10.4 10.4 14.7 32.4 30.4 33.9 21.5 15.5 15.2 13.3 [25] 19.2 27.3 26.0 30.4 15.8 19.7 15.0 21.4 > > my_tbbl = as_tibble(mtcars) > my_tbbl[, 1] # A tibble: 32 x 1 mpg <dbl> 1 21 2 21 3 22.8 4 21.4 5 18.7 6 18.1 7 14.3 8 24.4 9 22.8 10 19.2 # ... with 22 more rows
データmtcarsの1列目”mpg”を取り出したところ、data.frameではベクトル(リスト)として出力されているが、tibbleではtibbleとして出力されている。データ形式の変化に惑わされることなく、一貫して処理し続けることができる。
追記、2021年4月18日
tibbleを操作しながら、ノルウェー政府年金基金SWFのデータから、2019~2020年での構成銘柄における日本株の変化を読み解く記事を投稿した。関心があれば、併せて参照してほしい。
impsbl.hatenablog.jp
Tidy tools manifesto
Tidyverseが前提としている原則論がTidy tools manifestoだ。
1. Reuse existing data structures.
2. Compose simple functions with the pipe.
3. Embrace functional programming.
4. Design for humans.
データ構造の再利用は、tibbleを用いることで実践できる。目立つのはパイプ(%>%)の活用だろう。ある関数の出力結果を、パイプを用いて次の関数へ引き渡すという、単純な関数の連続的な連携によって、複雑なことを実現することで、コードの構造、可読性が向上する。
パイプ
関数の出力結果を、別の関数の引数として直接代入するために、関数を入れ子構造にすることがある。パイプを活用することで、そのような状況を避けることができる。
パイプで繋ぐことで、関数の出力結果は、次の関数の第1引数へ代入される。コードを確かめるのが分かりやすい。次のサンプルは、先のコードの続きだ。
🔎R code and output
> head(my_df) mpg cyl disp hp drat wt qsec vs am gear carb Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4 Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1 Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1 Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2 Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1 > head(my_tbbl) # A tibble: 6 x 11 mpg cyl disp hp drat wt qsec vs am gear carb <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> 1 21 6 160 110 3.9 2.62 16.5 0 1 4 4 2 21 6 160 110 3.9 2.88 17.0 0 1 4 4 3 22.8 4 108 93 3.85 2.32 18.6 1 1 4 1 4 21.4 6 258 110 3.08 3.22 19.4 1 0 3 1 5 18.7 8 360 175 3.15 3.44 17.0 0 0 3 2 6 18.1 6 225 105 2.76 3.46 20.2 1 0 3 1
data.frameに付与されていたラベルが、tibbleには存在しない。次のことを、パイプを駆使して実行する。
- my_tbblに列”label”を追加し、data.frameのラベルを代入する。
- 列"label"の名前を、"name"に変更する。
最初から列名は”name”とすれば良いのだが、あくまでもパイプの連携を示すサンプルとして、冗長な処理とした。コードと出力結果の一例だ。
🔎R code and output
> my_tbbl = my_tbbl %>% mutate(label = labels(mtcars)[[1]]) > my_tbbl$label [1] "Mazda RX4" "Mazda RX4 Wag" "Datsun 710" "Hornet 4 Drive" "Hornet Sportabout" [6] "Valiant" "Duster 360" "Merc 240D" "Merc 230" "Merc 280" [11] "Merc 280C" "Merc 450SE" "Merc 450SL" "Merc 450SLC" "Cadillac Fleetwood" [16] "Lincoln Continental" "Chrysler Imperial" "Fiat 128" "Honda Civic" "Toyota Corolla" [21] "Toyota Corona" "Dodge Challenger" "AMC Javelin" "Camaro Z28" "Pontiac Firebird" [26] "Fiat X1-9" "Porsche 914-2" "Lotus Europa" "Ford Pantera L" "Ferrari Dino" [31] "Maserati Bora" "Volvo 142E" > my_tbbl = my_tbbl %>% rename(name = label) > my_tbbl$name [1] "Mazda RX4" "Mazda RX4 Wag" "Datsun 710" "Hornet 4 Drive" "Hornet Sportabout" [6] "Valiant" "Duster 360" "Merc 240D" "Merc 230" "Merc 280" [11] "Merc 280C" "Merc 450SE" "Merc 450SL" "Merc 450SLC" "Cadillac Fleetwood" [16] "Lincoln Continental" "Chrysler Imperial" "Fiat 128" "Honda Civic" "Toyota Corolla" [21] "Toyota Corona" "Dodge Challenger" "AMC Javelin" "Camaro Z28" "Pontiac Firebird" [26] "Fiat X1-9" "Porsche 914-2" "Lotus Europa" "Ford Pantera L" "Ferrari Dino" [31] "Maserati Bora" "Volvo 142E"
もう少し高度なことを実践してみる。ラベルにはメーカー名とモデル名が含まれている。それは半角スペースで区切られているのだが、モデル名も半角スペースを含んでいる。この状況で、
- メーカー名とモデル名を分割する。
- メーカー名とモデル名を異なる列に格納する。
- メーカー名で列”mpg”(燃費)をグループ集計する(平均を求める)。
- (グループ集計したこれをこれを分割し、それぞれを異なる列に格納する。
- メーカー名(列”maker”)、平均燃費(列”mean”)で構成されるtibble”mpg_maker”を作成する。
- mpg_makerのレコードを列”mean”の降順で並べる。
特に3以降の処理は、パイプを駆使して1行で記述することができる。次のような具合だ。
🔎R code and output
my_labels = strsplit(labels(mtcars)[[1]], ' ') my_makers = c() my_models = c() for (i in 1:length(my_labels)){ my_makers = append(my_makers, my_labels[[i]][1]) my_models = append(my_models, paste(my_labels[[i]][-1], collapse = ' ')) } my_tbbl = my_tbbl %>% mutate(maker = my_makers) my_tbbl = my_tbbl %>% mutate(model = my_models) mpg_maker = my_tbbl %>% group_by(maker) %>% summarise(mean = mean(mpg)) %>% arrange(-mean)
> mpg_maker # A tibble: 22 x 2 maker mean <chr> <dbl> 1 Honda 30.4 2 Lotus 30.4 3 Fiat 29.8 4 Toyota 27.7 5 Porsche 26 6 Datsun 22.8 7 Volvo 21.4 8 Mazda 21 9 Hornet 20.0 10 Ferrari 19.7 # ... with 12 more rows
グラフの描画、重ね合わせ
グラフの描画には文法がある。それは次のような具合だ。
ggplot() + geom_・・・() + theme() ggplot() + stat_・・・() + theme()
ggplotは言うなればグラフを描画するキャンバスで、グラフ全体の諸設定(x、y軸やカテゴリごとの色分けなど)も定義する。続く”+”はggplotにおけるパイプだ。
geom~、stat~で個々のグラフについて定義し、themeでは見た目(ラベルや配置など)を定義する。
次の図はmpg_makerのバー・チャートを出力したものだ。makerの文字がかぶらないように、45度の傾斜をつけて配置している。
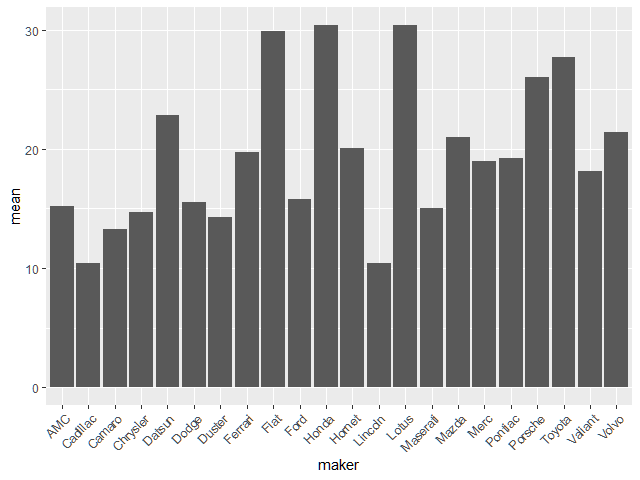
🔎R code
mpg_maker %>% ggplot(mapping = aes(x = maker, y = mean)) + geom_histogram(stat = 'identity') + theme(axis.text.x = element_text(angle = 45, hjust = 1))
グラフの重ね合わせにも、パイプを駆使して単純に対応できる。重ね合わせたいグラフをパイプで繋げばよい。グラフの上限下限や目盛り調整など不要だ。
バーチャートの上に点域を、さらに各データをプロットしている。その重ね合わせを示すために、順番に3つのグラフを一まとめに出力した。
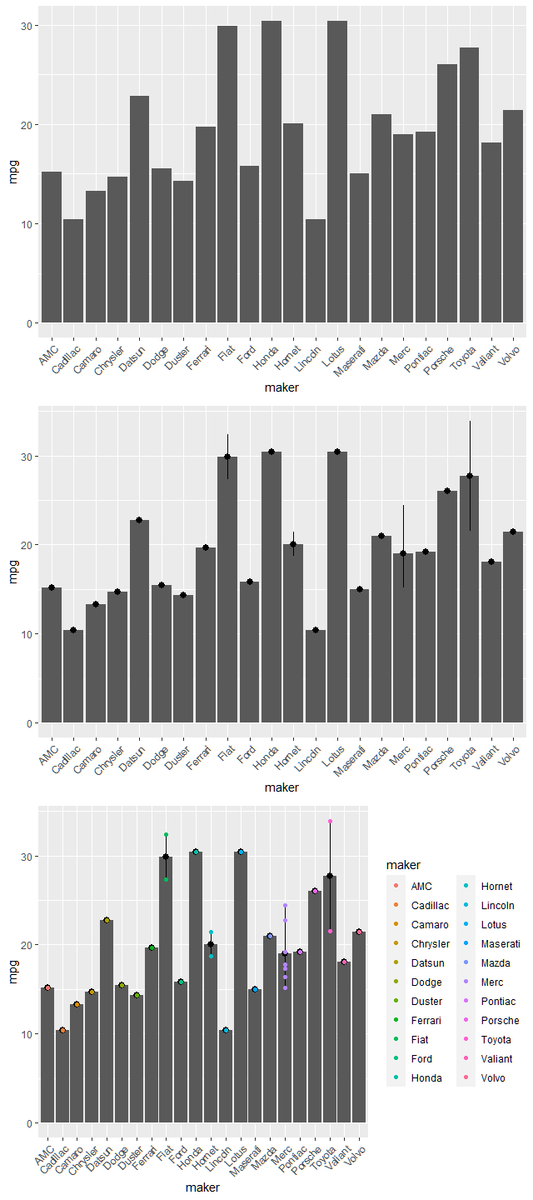
🔎R code
fig1 = ggplot(my_tbbl, mapping = aes(x = maker, y = mpg)) + stat_summary(geom = "bar", fun = "mean") + theme(axis.text.x = element_text(angle = 45, hjust = 1)) fig2 = fig1 + stat_summary(geom = "pointrange", fun = "mean", fun.max = "max", fun.min = "min") fig3 = fig2 + geom_point(mapping = aes(colour = maker)) gridExtra::grid.arrange(fig1, fig2, fig3)
fig3だけを出力する場合、次のように記述することもできる。単純に重ね合わせたいグラフをパイプで繋いでいるだけなのが理解できると思う。
🔎R code
ggplot(my_tbbl, mapping = aes(x = maker, y = mpg)) + stat_summary(geom = "bar", fun = "mean") + stat_summary(geom = "pointrange", fun = "mean", fun.max = "max", fun.min = "min")+ geom_point(mapping = aes(colour = maker)) + theme(axis.text.x = element_text(angle = 45, hjust = 1))
コード全文
🔎R code
library(tidyverse) head(mtcars) my_df = mtcars my_df[, 1] my_tbbl = as_tibble(mtcars) my_tbbl[, 1] head(my_df) head(my_tbbl) my_tbbl = my_tbbl %>% mutate(label = labels(mtcars)[[1]]) my_tbbl$label my_tbbl = my_tbbl %>% rename(name = label) my_tbbl$name my_tbbl$name my_labels = strsplit(labels(mtcars)[[1]], ' ') my_makers = c() my_models = c() for (i in 1:length(my_labels)){ my_makers = append(my_makers, my_labels[[i]][1]) my_models = append(my_models, paste(my_labels[[i]][-1], collapse = ' ')) } my_tbbl = my_tbbl %>% mutate(maker = my_makers) my_tbbl = my_tbbl %>% mutate(model = my_models) mpg_maker = my_tbbl %>% group_by(maker) %>% summarise(mean = mean(mpg)) %>% arrange(-mean) mpg_maker %>% ggplot(mapping = aes(x = maker, y = mean)) + geom_histogram(stat = 'identity') + theme(axis.text.x = element_text(angle = 45, hjust = 1)) fig1 = ggplot(my_tbbl, mapping = aes(x = maker, y = mpg)) + stat_summary(geom = "bar", fun = "mean") + theme(axis.text.x = element_text(angle = 45, hjust = 1)) fig2 = fig1 + stat_summary(geom = "pointrange", fun = "mean", fun.max = "max", fun.min = "min") fig3 = fig2 + geom_point(mapping = aes(colour = maker)) gridExtra::grid.arrange(fig1, fig2, fig3) ggplot(my_tbbl, mapping = aes(x = maker, y = mpg)) + stat_summary(geom = "bar", fun = "mean") + stat_summary(geom = "pointrange", fun = "mean", fun.max = "max", fun.min = "min")+ geom_point(mapping = aes(colour = maker)) + theme(axis.text.x = element_text(angle = 45, hjust = 1))