Scraping access from Singapore
 |
 |
よく見ると、シンガポールからのいつものアクセスではなく、日本からのアクセスが増えていることに気付いた。どうやらPicineと呼ばれる42 Tokyoの入試が実施されており、ページの存在を知った誰かを通じて、受験者内で情報が共有されたのかもしれない。特に今月の受験者には、ブログ投稿を参照している者が多いようだ。
シンガポールからの、本日のアクセスはいつもに比べて控えめだ。とはいえ、更新を知りたければRSSを利用すればよいのだし、多数のアーカイブ先を日に何度も繰り返し参照すること自体が無駄なのだ。
ベンチマーク
| 前日比順 | 年初来順 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|









海外
中国、インド、ブラジル
| 香港 | 0.04 | -2.61 |
| 上海 | 0.41 | 0.28 |
| ムンバイ | 0.09 | -0.26 |
| 1309 乖離率 | -1.28 | -0.88 |
| 1325 乖離率 | 1.85 | 1.76 |
| 1678 乖離率 | 0.87 | 0.22 |
| 1309 中国 |
 |
 |
| 1325 ブラジル |
 |
 |
| 1678 インド |
 |
 |
個別
PKSHA
 |
 |
楽天
 |
 |
[Open RANを巡る競争は楽天が一歩リードか ドコモと“協調”する可能性も?:embed:cite]
楽天のO-RANソフトウェアは競合と比べて最も成熟している
ビジネス面では楽天シンフォニーが先行していることもあり、OREX SAI設立に至ったドコモの動きには、「なんとなく1周遅れ感がある」(同)と手厳しい。
先にビジネスを拡大し、その中核ともいえるソフトウェアをオープン化していく点では、楽天がドコモを一歩リードしているようにも見える。三木谷氏が「1周遅れ」と語っていたのは、そのためだ。一方で、リアルOpen RANプログラムを開始したことで、ドコモと楽天が手を組める可能性も見えてきた。三木谷氏は、オープン化したvRANを「競合が利用するかもしれないが、それはそれでいい」と語る。

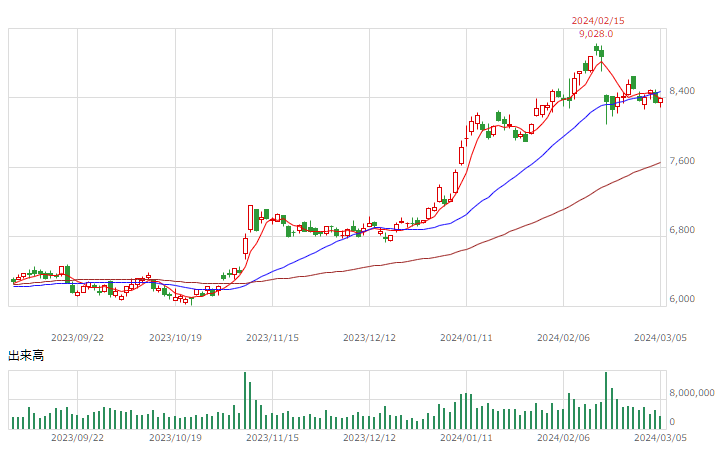
NTT
 |
 |
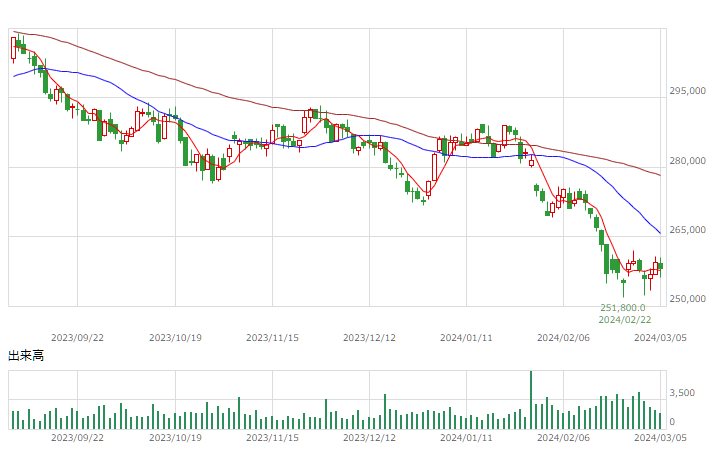
日本ロジスティクス
 |
 |
AI
画像生成AIモデルを使ってGPUの速度を比べてみた
| TensorCore | |
|---|---|
| Maxwell | |
| Pascal | |
| Volta | float 16bit |
| Turing | INT 8, 4, 1bit |
| Ampere | float 64, 16bit TensorFloat 32bit bfloat 16bit INT 8, 4, 1bit |
| Hopper | float 64, 16bit TensorFloat 32bit bfloat 16bit INT 8bit |
| Ada | |
| Lovelace |
Pascal以前は単位がほぼs/itとなっている
Volta以降は単位が全てit/sとなっている
実はTensorCoreという計算機能が実装された境目がここなんです。Volta世代からなんです。
低精度演算を想定していない以前のGPUでは、その精度によっては変換処理が発生してそれがオーバーヘッドになり、逆に「確かにメモリにはモデルが収まるけど、処理させたらめっちゃくちゃ遅い」って状況になりかねませんで、それに備えて登場したのがTensorCoreです。
TensorCoreはタダでさえ単純な演算に特化してるGPUのCUDAコア以上に特化度を上げていて、低精度演算時に行われる行列積の能力にウェイトをより置いた機能を持っています。
LLMを扱ったりする際にお世話になる flash-attention の機能ですが、あれはAmpere以降のGPUじゃないと動きませんのでご注意を・・・