| 年初来パフォーマンス順 | 前日比順 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
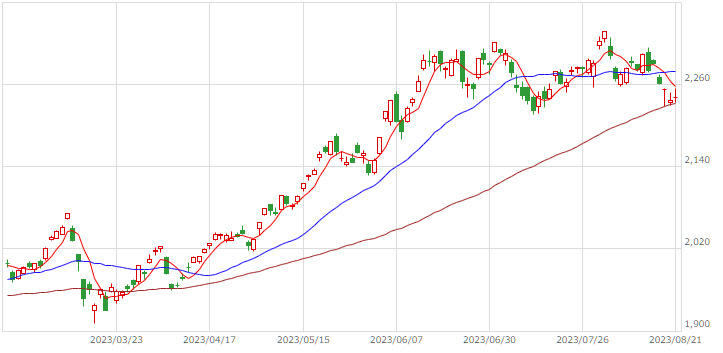
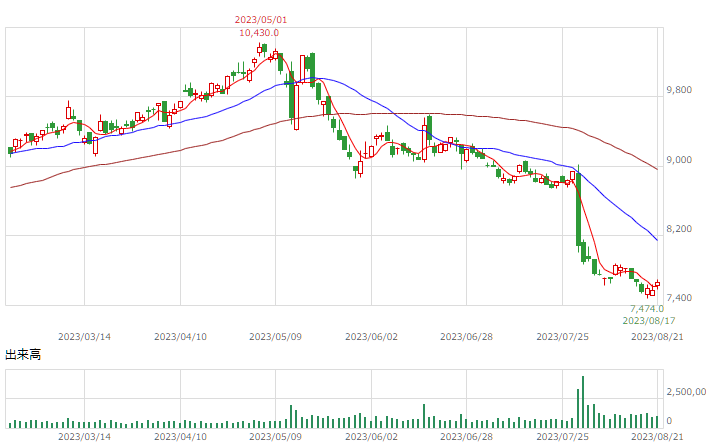
| TOPIX | 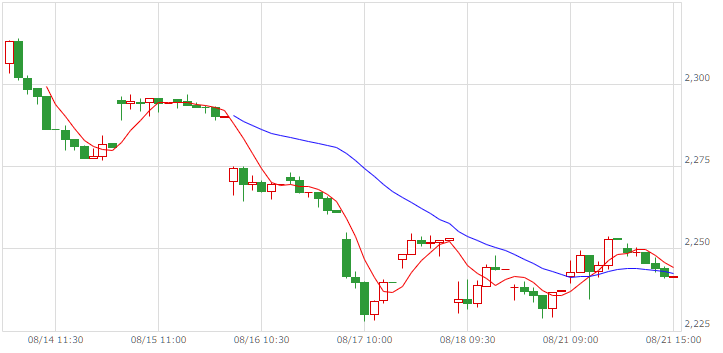 |
 |
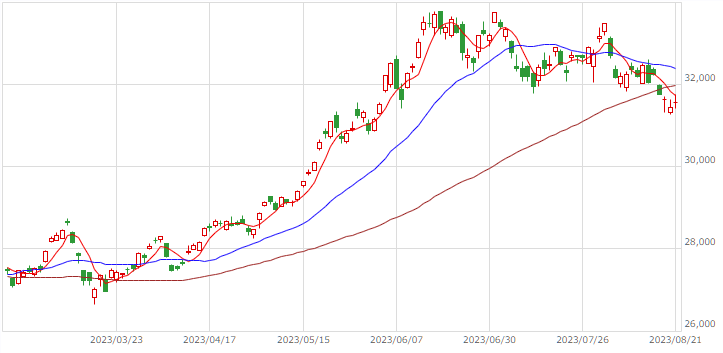
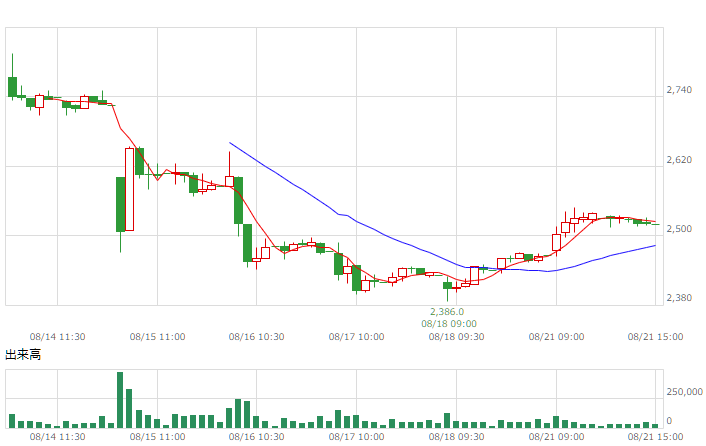
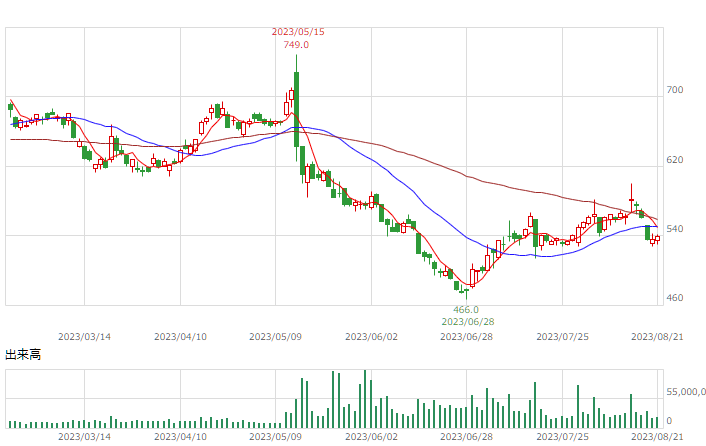
| 日経225JPY | 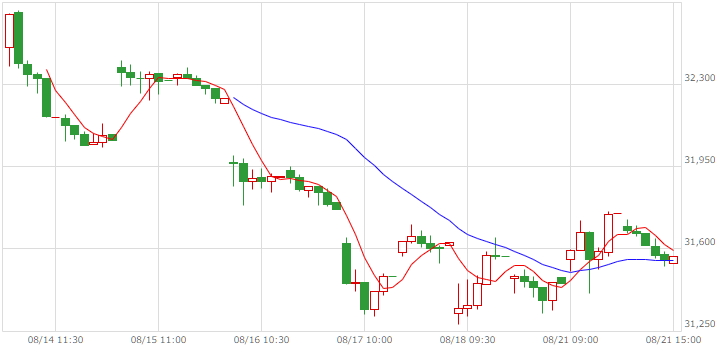 |
 |
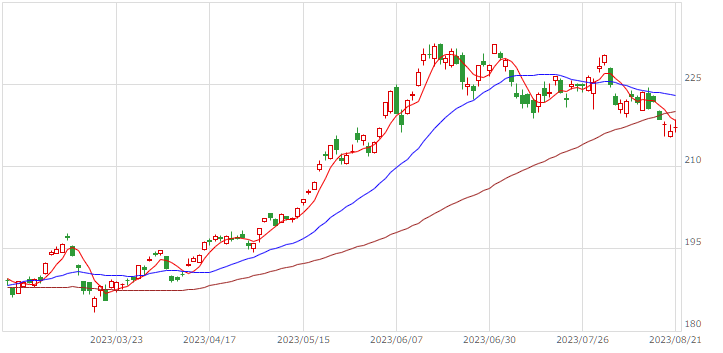
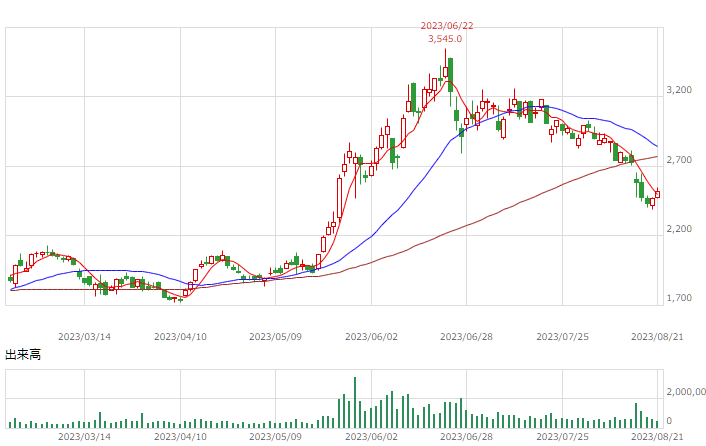
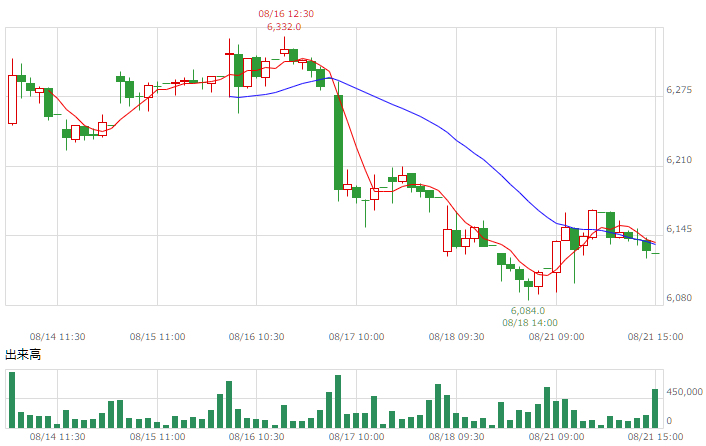
| 日経225USD | 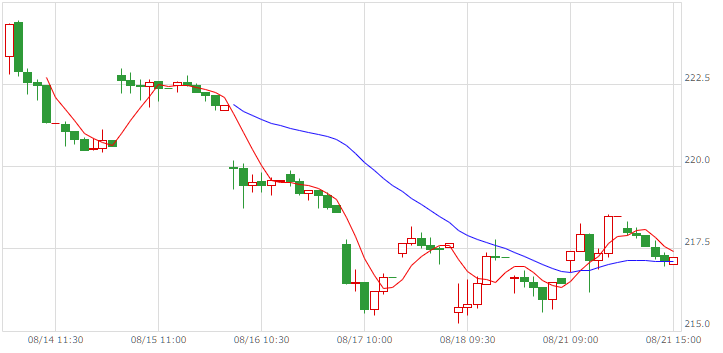 |
 |
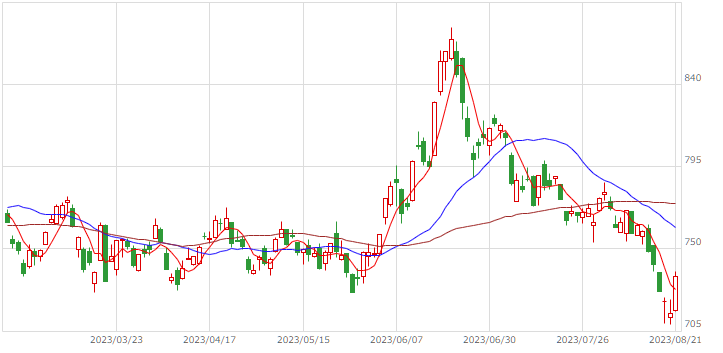
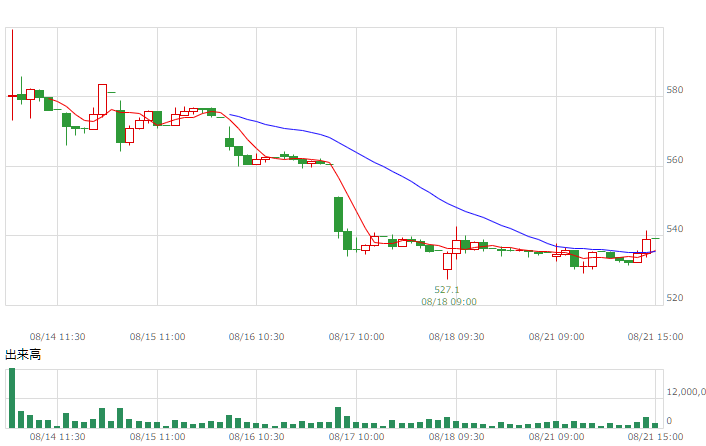
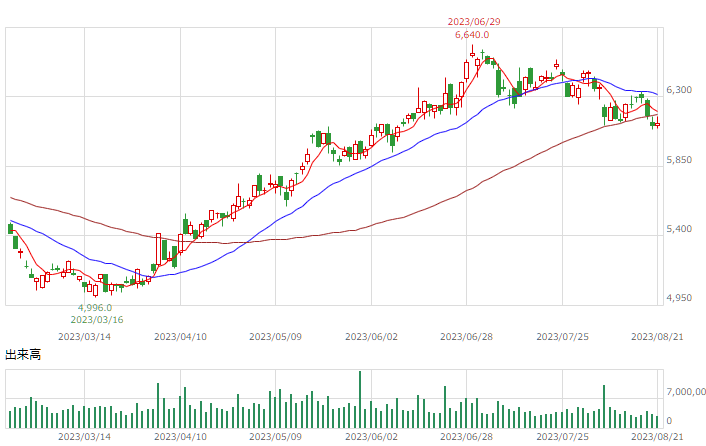
| マザーズ | 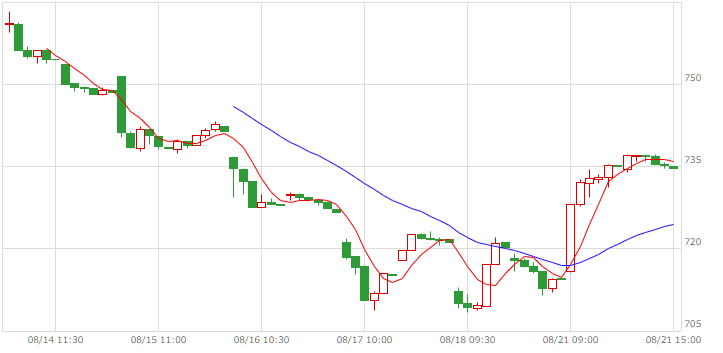 |
 |
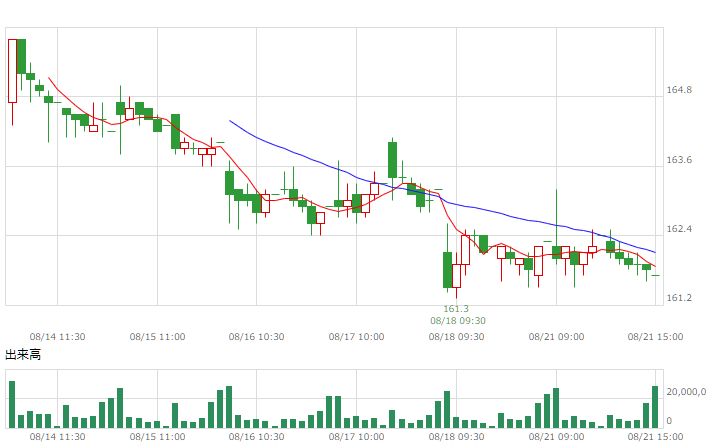
| REIT | 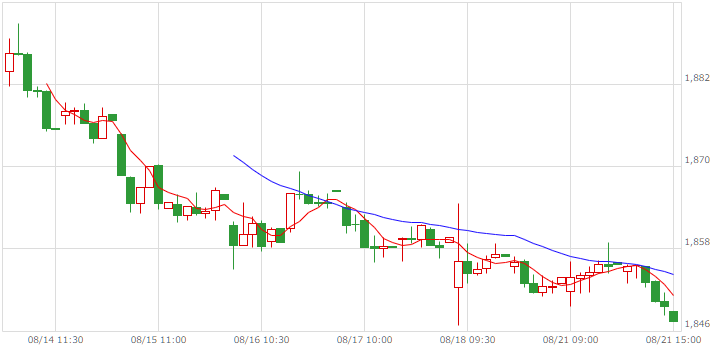 |
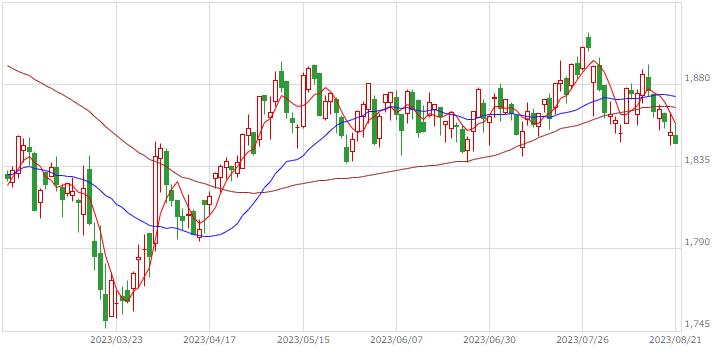 |
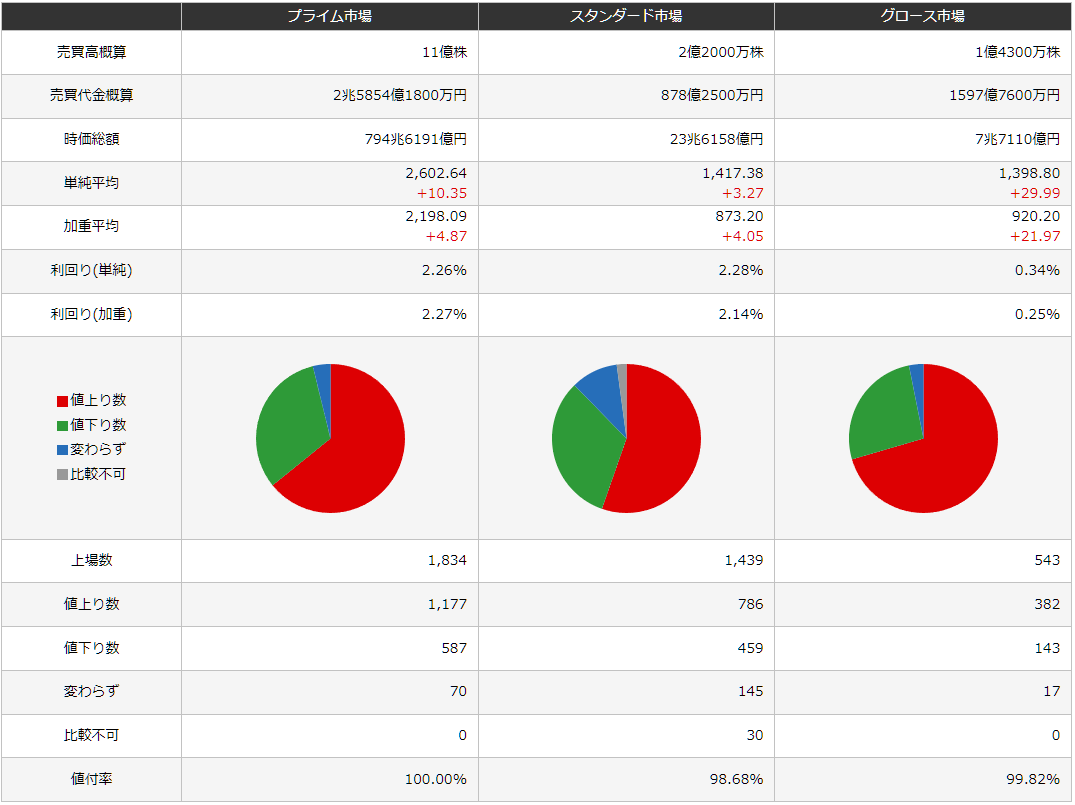
中国市場、インド市場
| 中国 | 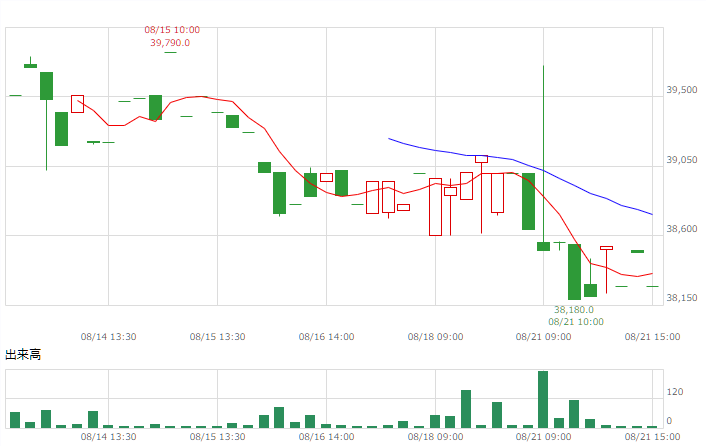 |
 |
| インド | 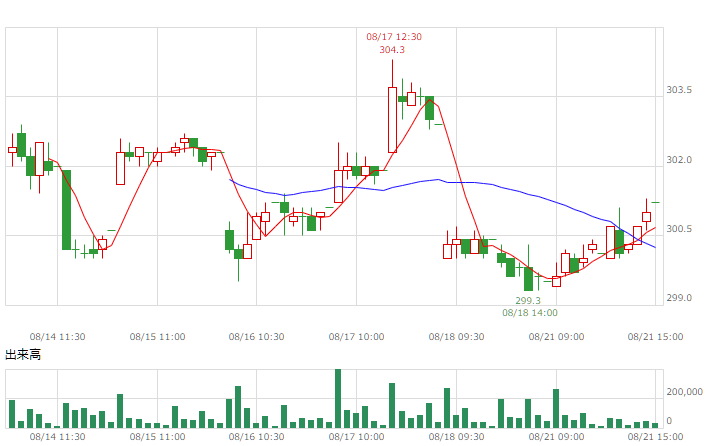 |
 |
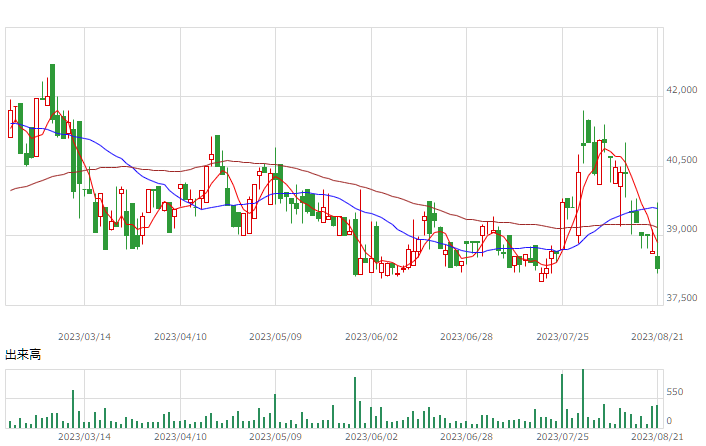
| 8月21日 | 香港ハンセン | -1.82 |
| 上海総合 | -1.24 | |
| SENSEX30 | 0.41 | |
| 1309乖離率 | -2.72 | |
| 1678乖離率 | 0.60 |
世界の指数・長期金利 - Yahoo!ファイナンス
ウエルスアドバイザー [ ETF乖離時系列 ]
ウエルスアドバイザー [ ETF乖離時系列 ]
インデックス投資ナイトのスピーチ原稿
note.com
山崎元の存在を知ったのは、転職の話題がきっかけだった。2000年頃、同士が登場する場面の多くで取り扱われる話題は、転職のことだった。仕事の内容、背景は置いて、私も短期転職を繰り返しており、同氏のような考え方が一般的にならないものか、と思っていた。
そのうち村上龍のメールメディア*1に経済分野の論客として登場し、専門分野である投資の話題、特にインデックス投資を語る場面が増え、今やこちらが主戦場になっている印象だ。
転職はすでに一般的なものとなり、特にIT業界では短期転職も「ある程度」は受容されるようにはなった。個人投資家はそれほど多くはないとはいえ、インデックス投資、いわゆるオルカン投信への長期積み立ては、その定石として知られるようになった。
年初、患っていたガンから回復した、という話題*2があったと思っていたら、再発したのだという。そして、どうやら先は長くなさそうだ、と予感させる言及もある。
持ち家と賃貸の比較や、幸せについてなど、これまで見かけることのなかった話題が同氏のコラムで取り上げられていたのは、このような背景があったからなのかもしれない。
昨年手術して治療した癌が、転移・再発してしまった。いわゆるステージⅣの癌患者です。
「予想」と「希望」を意識的に分けることの重要性
自分の「持ち時間」を数ヶ月から一年くらいと見積もって、その時間を有効に使うことを考えています。
来年も、再来年も会えるといいのですが、
AI
karpathy/llama2.c
Clear Linuxで、次のコマンドを実行したところ、何も問題なく文章が出力された。第7世代のIntel Core i5 + 8GB RAMの環境で、50~60トークン/秒のパフォーマンスだった。
mkdir 20230821 cd 20230821 git clone https://github.com/karpathy/llama2.c.git # model checkpoint # 学習のパラメータ、途中経過を保存したもの。 cd llama2.c wget https://huggingface.co/karpathy/tinyllamas/resolve/main/stories15M.bin make run ./run stories15M.bin
ここまでが「feel the magic」の前半。問題はLlama 2モデルの生成と強化学習だ。MetaにLlama2モデルへのアクセスを承認してもらい、ダウンロードする。その後で「Meta's Llama 2 models」の作業に着手する。25GBのファイルが生成されるのだという。Google Colabでは対応できない。
それが終わっても、96スレッドのLinuxマシン上での推論パフォーマンスは、4トークン/秒だったという。M1 MacBook Airでは、1トークンを処理するのに30秒を要したという。私の環境で挑戦してみる価値は少なそうだ。「models」で紹介されている、小規模学習モデルを使用する話題へ直行するのが良いだろう。
「models」は、このレポジトリの一番の目玉であり、私自身のお目当てでもある。一方、気になる記述がある。4つのGPUで分散処理して1日…
I ran using Distributed Data Parallel (DDP) on 4 GPUs on my cloud machine, training took ~day or so.
"Chinchilla paper"の論文終盤に掲載されている表を基に、パラメータ調整するのが主な作業になるはずなので、極小モデルの生成には挑戦はしてみようか。あるいは、この話題も飛ばして「custom tokenizer」に着手するか。